[211201] 코딩 테스트를 위한 파이썬 문법 1편 (Python Basic)
모든 게시물은 macOS Monterey 12.0.1 버전을 기준으로 작성하였습니다.
저서 '이것이 취업을 위한 코딩 테스트다 with 파이썬'을 바탕으로 작성하였습니다.
수 자료형
프로그래밍은 결국 데이터를 다루는 행위다.
파이썬의 자료형에는 정수형, 실수형, 복소수형, 문자열, 리스트, 튜플, 딕셔너리 등이 있다.
많은 코딩 테스트에서 특히 정수형을 다루는 문제가 출제된다.

최단 경로로 가능한 최댓값이 10억 미만이라면 무한(INF)을 표현할 때 10억을 이용할 수 있는데
이때 일일이 10억을 특정 변수에 대입하는 일은 번거로워 지수 표현 방식인 1e9로 표현할 수 있는 것이다.
혹은 987,654,321이라고 적으면 1e9와 유사할 정도로 크므로 이렇게 적기도 한다.

보통 컴퓨터 시스템은 실수를 처리할 때 부동 소수점 방식을 이용한다.
오늘날 가장 널리 쓰이는 IEEE754 표준에서는 실수형을 저장하기 위해 4바이트, 8바이트 등
고정된 크기의 메모리를 할당하기에 현대 컴퓨터는 실수를 표현함에 있어 그 정확도에 한계를 지닌다.
컴퓨터는 실수를 정확히 표현하지 못한다는 사실만 기억하고 주의하자.

따라서 소수점 값을 비교하는 작업이 필요한 문제라면 원하는 결과를 얻지 못할 수 있는데 이때 round 함수를 쓴다.
round() 를 호출할 때는 첫 번째 인자에 실수형 데이터를, 두 번째 인자에 (반올림하고자 하는 위치 -1)를 넣는다.
그 예로 123.456을 소수점 셋째 자리에서 반올림하려면 round(123.456, 2)라고 작성하고 결과는 123.46이다.
"123.456을 소수점 아래 둘째 자리까지 표현하자 ~" 라고 이해하자.
두 번째 인자를 넣지 않으면 소수점 첫째 자리에서 반올림한다.
흔히 코딩 테스트 문제에서는 실수형 데이터를 비교할 때 소수점 다섯 번째 자리에서 반올림한 결과가 같으면 답으로 친다.
a = 0.3 + 0.6
if round(a,4) == 0.9:
print(True)
else:
print(False)
수 자료형에 대해 나누기 연산자(/)와 몫 연산자(//) 그리고 나머지 연산자(%)를 자주 사용하게 된다.
파이썬에서 나누기 연산자(/)는 나눠진 결과를 기본적으로 실수형으로 처리한다.

리스트 자료형
리스트는 여러 개의 데이터를 연속적으로 담아 처리하기 위해 사용되는 자료형이다.
대괄호 안에 원소를 넣어 초기화하며 인덱스는 0부터 시작한다.
비어 있는 리스트를 선언할 때는 list() 혹은 [] 를 이용할 수 있다.

인덱스값을 입력하여 리스트의 특정 원소에 접근하는 것을 인덱싱(indexing)이라고 한다.
인덱스값은 양의 정수와 음의 정수 모두 사용할 수 있으며, 음의 정수를 넣으면 원소를 거꾸로 탐색하게 된다.
또한 리스트에서 연속적인 위치를 갖는 원소들을 가져와야 할 때는 슬라이싱(slicing)을 이용한다.
대괄호 안에 콜론(:)을 넣어 시작 인덱스와 (끝 인덱스-1)을 설정할 수 있다.
예를 들어 리스트의 두 번째 원소부터 네 번째 원소까지의 리스트를 가져오고 싶다면 a[1:4]
리스트 컴프리헨션은 리스트를 초기화하는 방법 중 하나로 대괄호 안에 조건문과 반복문을 넣어 활용한다.
# 0부터 19까지의 수 중에서 홀수만 포함하는 리스트
array = [i for i in range(20) if i % 2 == 1 ]
print(array)
-> 출력값 = [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
# 1부터 9까지의 수의 제곱 값을 포함하는 리스트
array = [i*i for i in range(1,10)]
print(array)
-> 출력값 = [1, 4, 9, 16, 25, 36, 49, 64, 81]
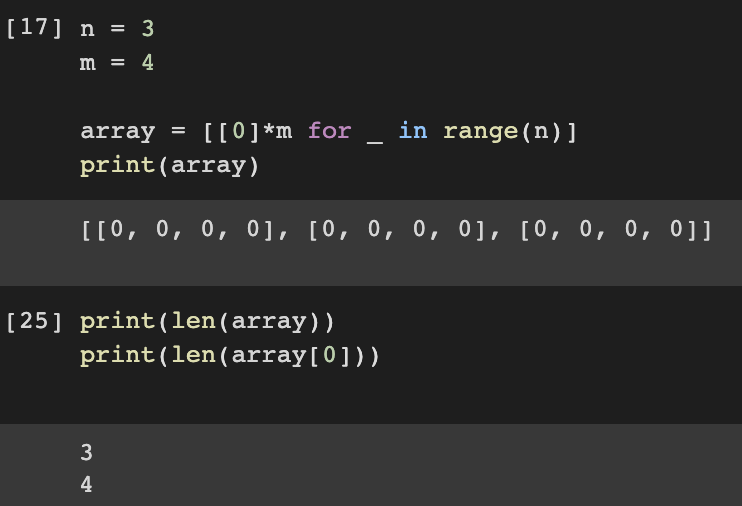
이러한 리스트 컴프리헨션은 코딩 테스트에서 2차원 리스트를 초기화할 때 매우 효과적이다.
예를 들어 N X M 크기의 2차원 리스트를 초기화할 때는 다음과 같이 사용한다.
# N X M 크기의 2차원 리스트 초기화
n = 3
m = 4
array = [[0] * m for _ in range(n)]
print(array)
-> 출력값 = [[0,0,0,0], [0,0,0,0], [0,0,0,0]]
-> 해설 = [0]을 4번 곱하면 [0,0,0,0]. 이를 3번 반복하여 2차원 만든다.
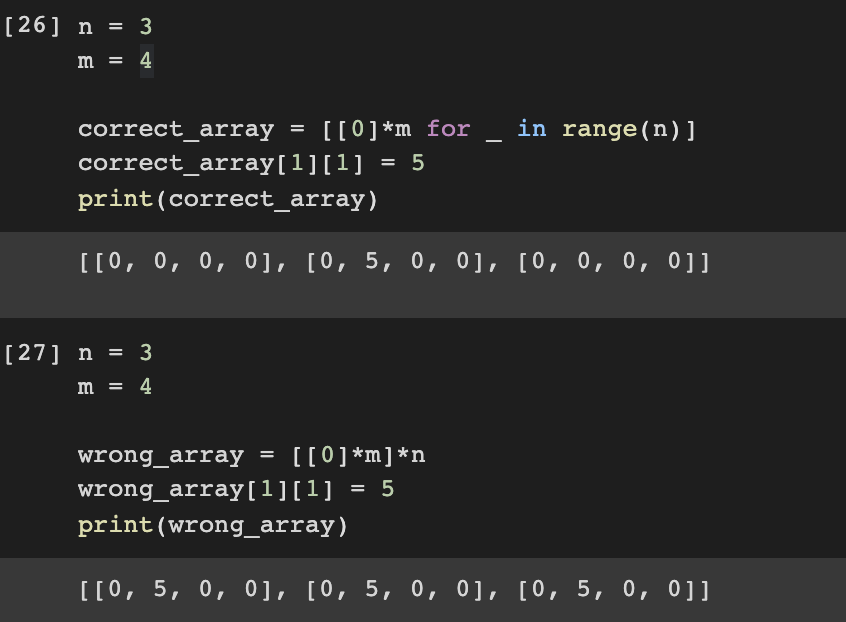
특정 크기의 2차원 리스트를 초기화할 때는 반드시 리스트 컴프리헨션을 이용해야 한다.
단순히 리스트 객체 자체를 곱하면 길이가 m인 리스트를 n만큼 그 참조값을 복사하는 것과 같다.
따라서 아래 [27]과 같이 잘못된 방법으로 초기화하면 전체 리스트 속 각 리스트가 같은 객체로 인식된다.
언더바는 어떤 역할일까?
반복을 수행하되 반복을 위한 변수의 값을 무시할 때 언더바를 사용한다.
예를 들어 1부터 9까지의 자연수를 더할 때는
summary = 0
for i in range(1,10):
summary += i
와 같이 i가 필요하지만
"hello"를 5번 출력할 때는
for _ in range(5):
print("hello")
와 같이 i가 필요하지 않으므로 언더바를 활용한다.
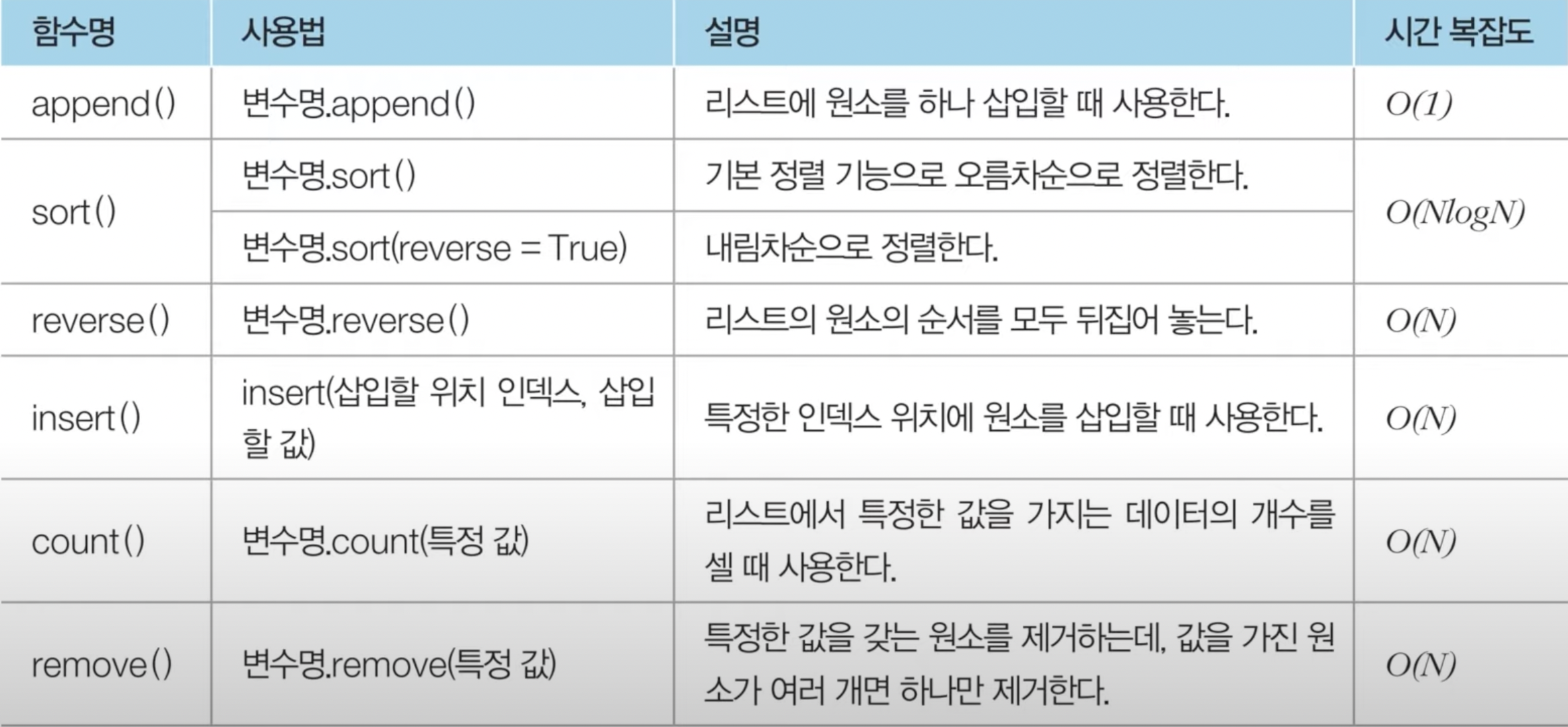
리스트와 관련한 기타 메서드는 위 테이블과 같다.
이 중에서 insert(), append(), remove()를 특히 더 강조한다.
코딩 테스트에서 insert 함수를 사용할 때 시간 복잡도는 O(N)이다.
파이썬의 리스트 자료형의 append 함수는 O(1)에 수행되는 데에 반해 insert 함수는 느리다.
중간에 원소를 삽입한 뒤에, 리스트의 원소 위치를 조정해줘야 하기 때문이다.
따라서 insert 함수를 남발하면 time limit으로 테스트를 통과하지 못할 수도 있다.
remove 함수 역시 O(N)이라는 점에 주의하자.
그러면 특정한 값의 원소를 모두 제거하려면 어떻게 해야 할까?
a = [1, 2, 3, 4, 5, 5, 5]
remove_set = {3, 5}
# remove_set에 포함되지 않은 값만을 저장
result = [i for i in a if not in remove_set]
print(result)
-> 출력값 = [1, 2, 4]
아래는 리스트 관련 기타 메서드의 출력값이다.


문자열 자료형
다른 프로그래밍 언어에서는 큰 따옴표로 문자열을, 작은 따옴표로 문자 하나하나를 초기화하는 반면에
파이썬에서는 큰 따옴표와 작은 따옴표를 모두 문자열 초기화에 사용할 수 있다.
또, 문자열 안에 큰 따옴표나 작은 따옴표를 포함시켜야 할 경우가 있는데
- 전체 문자열을 큰 따옴표로 구성하는 경우, 내부적으로 작은 따옴표를 포함할 수 있다.
- 전체 문자열을 작은 따옴표로 구성하는 경우, 내부적으로 큰 따옴표를 포함할 수 있다.
- +) 혹은 백슬래시(\)를 사용하면 큰 따옴표나 작은 따옴표를 원하는 만큼 포함시킬 수 있다.
- +) 백슬래시와 같은 문자를 이스케이프 문자로 정해두고 큰따옴표를 출력하는 등의 특별한 목적으로 사용한다.
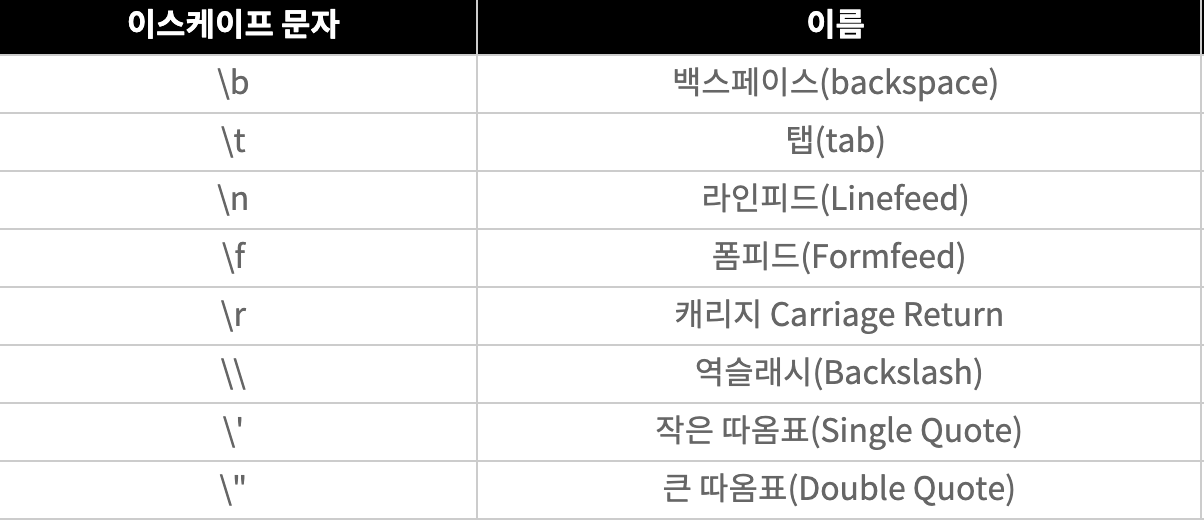
이를 잘 활용해야 하는 것이 코드업 기초 100제에 아래와 같은 문제가 있었고 오답을 몇번이나 냈는지 모른다,,
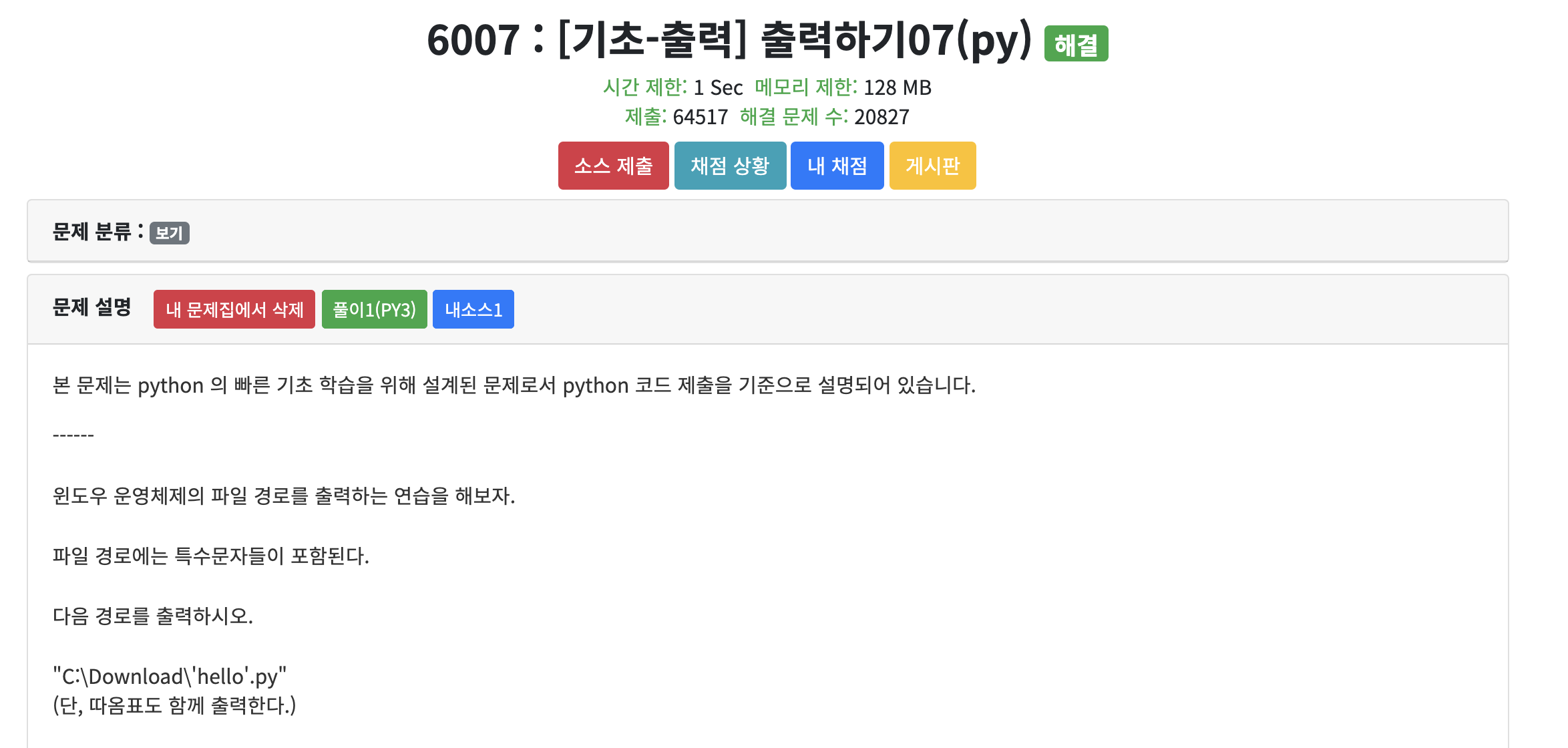
print(" \" C:\Download\ \' hello \' .py \" ")
조금 더 잘 보이게 이스케이프 문자를 사용한 부분은 띄어쓰기를 양쪽으로 해뒀다.
아래는 책에 있던 예시다.
또한 문자열은 다양한 연산기호를 활용하여 만들 수 있다.
+ : 문자열이 더해져 연결(Concatenate)된다.
x : 문자열이 그 값만큼 여러번 더해져 연결된다.
문자열 역시 인덱싱과 슬라이싱을 이용할 수 있으나 특정 인덱스의 값을 변경할 수는 없다. (Immutable)

튜플 자료형
튜플 자료형은 리스트와 거의 비슷한데 다음과 같은 차이가 존재한다.
튜플은 한 번 선언된 값을 변경할 수 없다.
리스트는 대괄호 [ ], 튜플은 소괄호 ( )를 이용한다.
튜플은 특히 그래프 알고리즘을 구현할 때 자주 사용된다.
예를 들어, 다익스트라 최단 경로 알고리즘 내부에서는 우선순위 큐를 이용하는데
해당 알고리즘에서 우선순위 큐에 한 번 들어간 값은 변경되지 않는다.
이처럼 알고리즘을 구현하는 과정에서 일부러 튜플을 이용하여
혹여나 잘못 작성하여 변경하면 안 되는 값이 변경되고 있지는 않은지 체크할 수 있고,
리스트에 비해 공간 효율적이며, 일반적으로 각 원소의 성질이 다를 때 이용한다.
앞서 언급한 다익스트라 알고리즘에서는 '비용'과 '노드'라는 서로 다른 성질의 데이터를
(비용, 노드 번호)와 같이 튜플로 함께 묶어서 관리하는 것이 관례이다.
튜플을 사용하면 좋은 경우를 정리해보면
- 서로 다른 성질의 데이터를 묶어서 관리해야 할 떄
- 데이터의 나열을 Hashing의 키 값으로 사용해야 할 때
- 리스트보다 메모리를 효율적으로 사용해야 할 떄
사전 자료형
사전 자료형은 키(Key)와 값(Value)의 쌍을 데이터로 가지는 자료형이다.
앞서 다루었던 리스트나 튜플이 값을 순차적으로 저장하는 것과는 대비된다.
파이썬의 사전 자료형은 내부적으로 Hash Table을 사용하므로 데이터 검색 및 수정이 O(1)로 처리가 가능하다.
이러한 사전 자료형은 코딩 테스트에서도 자주 사용될 수 있다.
예를 들어, 학생의 번호가 1부터 10,000,000까지로 구성되어 있는 상황에서 최대 10,000명의 학생을 고르자.
이후 특정한 학생 번호가 주어졌을 때 해당 학생이 선택되었는지를 어떻게 빠르게 알 수 있을까?
만약 리스트를 이용한다면 1 ~ 10,000,000 까지의 각 번호가 '선택되었는지를 저장하는' 리스트가 필요하다.
10,000개를 제외한 999만 개 가량의 데이터가 쓸모없는 데이터가 된다.
사전 자료형에 특정한 원소가 있는지 검사할 때는 '원소 in 사전' 을 사용하며, 이는 리스트, 튜플에서도 가능하다.
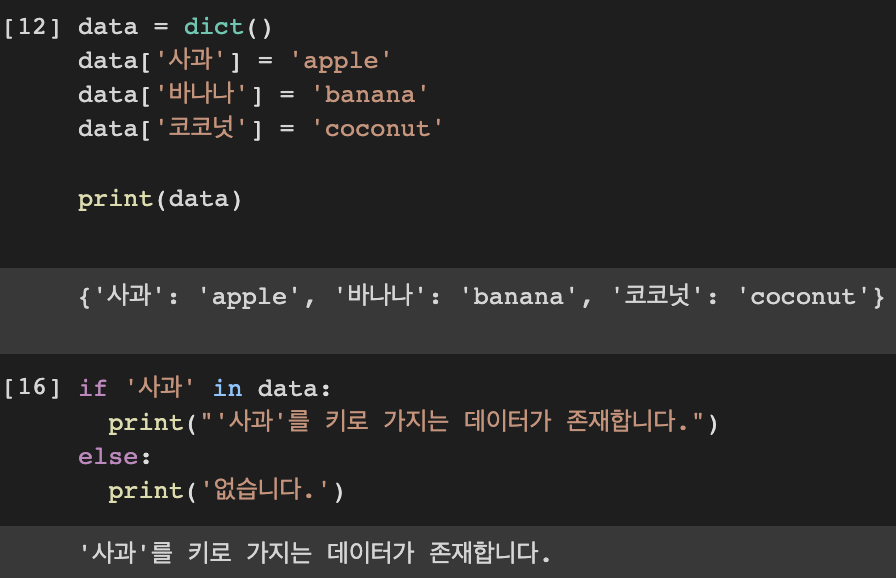
또한 사전 자료형에서는 키와 값을 별도로 뽑아내기 위한 메서드를 지원한다.
- 키 데이터만 뽑아서 리스트로 이용할 때는 keys() 함수를 이용한다.
- 값 데이터만 뽑아서 리스트로 이용할 때는 values() 함수를 이용한다.

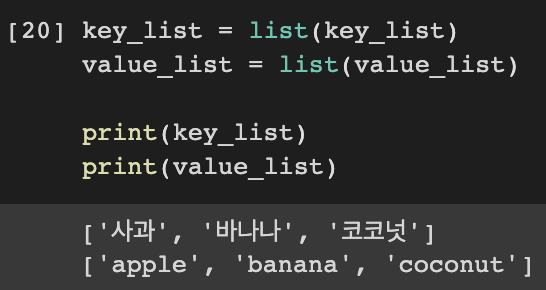
하지만 엄밀히 말하면 Dictionary Key 혹은 Dictionary Value라는 객체를 반환하기에
리스트로 사용하고 싶다면 list() 함수를 통해 형 변환을 진행해야 한다.
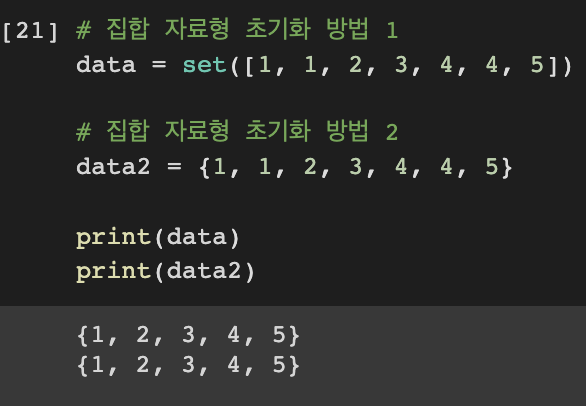
집합 자료형
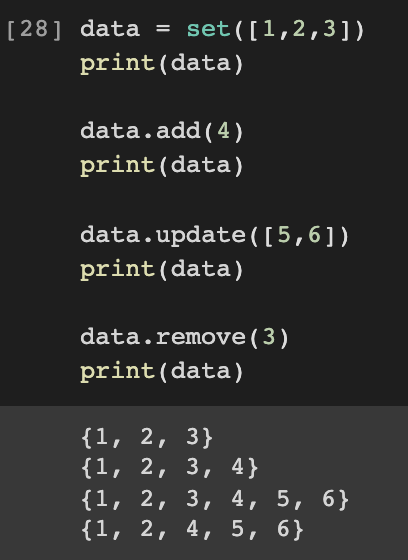
집합 자료형은 집합을 처리하기 위한 자료형으로 set() 함수로 리스트나 문자열을 집합으로 바꿀 수 있다.
집합의 경우, 중복을 허용하지 않고 순서가 존재하지 않는다는 특징이 있다.
리스트나 튜플은 순서가 있어 인덱싱을 통해 자료형의 값을 얻을 수 있었지만
사전과 집합은 인덱싱으로는 자료형의 값을 얻을 수 없으며 특히 집합 자료형의 경우, Key 없이 Value만 존재한다.
집합 자료형은 특히 '특정한 데이터가 이미 등장한 적이 있는지 여부'를 체크할 때 매우 효과적이다.
초기화하는 방법은 앞서 언급했던 set() 함수나 중괄호 { } 를 이용하면 된다.
집합 자료형의 연산으로는 합집합, 교집합, 차집합이 있다.
또한 관련 함수로는 add(), update(), remove()가 있으며,
데이터의 조회 및 수정에 있어서 O(1)의 시간에 처리가 가능하다.