다양한 블로그와 kaggle, github 그리고 논문을 참고하여 작성한 게시물입니다.
참고문헌은 게시물 하단에 기록하였습니다.
설명 가능한 AI ( eXplainable AI : XAI )
교내 학회(KUBIG) 의료영상 분석 프로젝트의 일환으로 미니 프로젝트를 각자 진행하기로 하였다.
앞선 게시물에서 다뤘던 Segmentation 모델로 유명한 U-net 논문을 리뷰하고 구현하려 했었으나
다른 학회원분과 주제가 완전히 겹치기도 했고, 데이터를 가공하고 모델을 구축하여 학습을 진행해도
그 프로젝트의 결과를 '인간의 관점'에서 해석하는 것이 매우 중요하다. 때문에 인공지능과 관련된
이슈들에 XAI가 빠지지 않는 것이 아닐까? 또, 이전에 구현에 실패한 경험 有. 그래서 이 주제를 골랐다.
구글링을 열심히 해보면 CAM, Grad-CAM을 포함한 다양한 Visualization 을 구현한 코드들은
Pretrained Model 을 가져와 model.eval() 로 Inference Mode 전환하고, 학습 없이 시각화를 한다.
하지만 나는 X-ray Image 에서 COVID-19 환자와 그렇지 않은 경우를 구분하는 Task 를 진행하고 싶으니
Fine-tuning 후에 Activation Based Method인 Grad-CAM Visualization 을 진행하기로 했다.
Pytorch 코드 구현
1. Dataset

2주 내로 유의미한 결과물을 만들어야 했고, 무엇보다 이번 프로젝트는 학습에 포커스를 둔 것이 아니기에
CPU로도 그 성능을 볼 수 있을 정도의 소규모 데이터와 가벼운 모델을 활용하여 진행하였다.
covid, normal 각 케이스마다 162장의 이미지가 존재하였고, 모델은 pretrained ResNet18 을 사용했다.
2. Data Preprocessing
ImageTransform이라는 class를 만들어 phase가 'train'일 때와 'val'일 때 다르게 작동하도록 하였다.

# 정상 케이스 예시


# COVID-19 예시

3. Data Loader
normal case = 0, covid case = 1로 Labeling한 Dataset을 만든다.
Batch Size를 지정하고 torch.utils.data.DataLoader로 훈련, 검증 데이터 로더를 만든다.

4. Model
Pretrained ResNet18 모델을 불러오고, 뒤에 Fully-Connected Layer 붙여서 마무리

Hyperparameter는 마음껏 조절해서 사용해도 괜찮다.
5. Train


6. Grad-CAM
학습시킨 모델까지 있다면 준비는 끝났다.






논문 리뷰
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization

본 논문은 ICCV 2017 발표된 논문으로 CAM의 Generalized Version이라고 생각하면 좋다.
방법 자체가 유사하기 때문에 CAM 논문을 본 후에 해당 논문을 보는 것이 좋다.
하단에 두 논문 링크를 모두 달아놓았으니 관심이 있으신 분들은 참고하여 공부하시길 ~
본격적으로 Grad-CAM에 대해 알아보기 전에 CAM 논문을 통해 개념을 대략적으로 잡고 넘어가자.
CAM : Class Activation Mapping
CAM 논문을 읽어봤다면 Grad-CAM과의 차이를 바로 눈치챘을 것이다.
CAM의 경우, CNN의 마지막 Feature Map을 Global Average Pooling 한 뒤에 ( 평균을 낸 뒤에 )
Weight를 각 Feature Map들에 곱해줌으로써 Target Image의 Label을 결정함에 있어
중요하게 사용되었던 Feature Map을 추출할 수 있다는 것이 그 개념이다.
그렇게 추출된 Feature Map들을 병합하면 높은 Gradient가 축적된 부분이
곧 이미지에서 해당 Label이라고 판단함에 있어 중요한 역할을 한 부분일 것이다.
직관적으로 이를 설명해주는 Figure를 보자.

하지만 CAM은 GAP Layer에만 적용할 수 있으므로 다음 CNN에는 사용할 수 없다.
1. CNNs with fully-connected layers (e.g. VGG)
2. CNNs for structured outputs (e.g. captioning)
3. CNNs used in tasks with multi-modal inputs (e.g. LSTM 뒤에 붙는 Visual QnA)
이러한 단점을 개선하자.
Grad-CAM
Grad-CAM은 Final Convolution Layer로 흘러 들어가는 Gradient를 사용하여 target image의
중요한 영역 (concept를 예측하기 위해 중요한 영역)을 강조하는 Localization Map을 만든다.
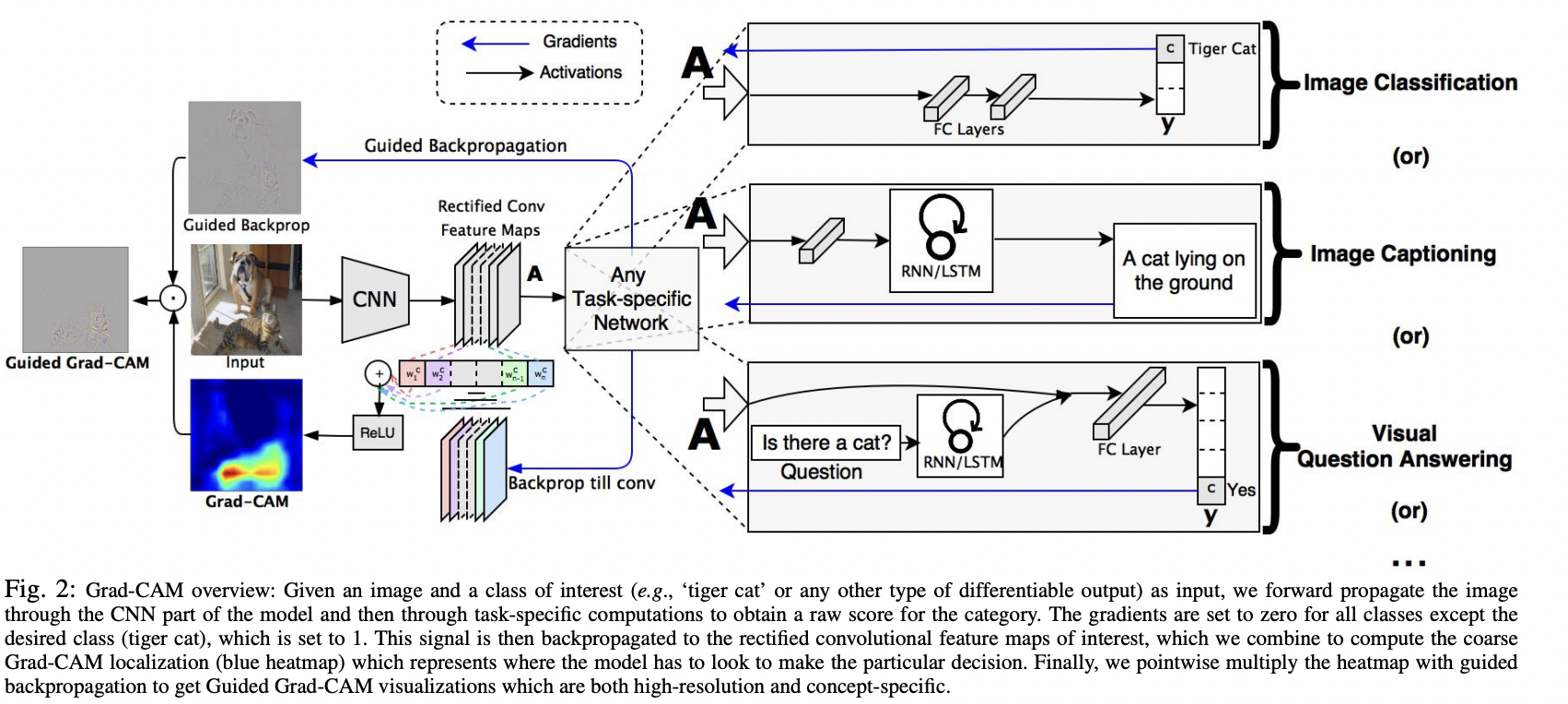
이미지 분류를 먼저 보면 Tiger cat이라고 판단하였는데 이렇게 예측하기 위한 Score 값은 y^(c)가 될텐데
이를 우리가 원하는 Feature Map으로 (마지막 Conv Layer으로) Back Propagation 계산한다. (미분한다)

빨간 상자가 의미하는 것은 k번째 Feature Map이 y^(c)라는 class score에 미치는 영향력이다.
이를 Feature Map의 각 픽셀들에 대해 계산을 한다면 각 픽셀값이 class를 예측하는데 얼마나
영향을 끼쳤는지 그 영향력을 의미하게 된다.

위에서 구한 alpha^(k)를 Feature Map과 곱해주는데 이 부분이 CAM의 원리가 담긴 부분이다.
ReLU 속 선형결합은 feature map을 가중치에 따라 다르게 표현하는데
여기서 ReLU를 사용했다는 것이 인상적이다. 만약 가중치를 곱한 값이 음의 값을 가지면
즉, class가 아닌 다른 부분들은 다 제외한다는 의미다.
여기서 CNN의 마지막에 GAP를 사용하면 CAM과 같아진다.
다만, Grad-CAM은 GAP가 없어도 그 시각화가 가능하다는 점이 비교적 용이하다.
[ 참고문헌 ]
https://arxiv.org/abs/1512.04150
Learning Deep Features for Discriminative Localization
In this work, we revisit the global average pooling layer proposed in [13], and shed light on how it explicitly enables the convolutional neural network to have remarkable localization ability despite being trained on image-level labels. While this techniq
arxiv.org
https://arxiv.org/abs/1610.02391
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
We propose a technique for producing "visual explanations" for decisions from a large class of CNN-based models, making them more transparent. Our approach - Gradient-weighted Class Activation Mapping (Grad-CAM), uses the gradients of any target concept, f
arxiv.org
GitHub - PeterKim1/paper_code_review: paper review with codes
paper review with codes. Contribute to PeterKim1/paper_code_review development by creating an account on GitHub.
github.com
https://www.kaggle.com/ankitachoudhury01/covid-patients-chest-xray
Covid Patients Chest X-Ray
Download 162 images of covid patients and normal patients chest X-ray.
www.kaggle.com