모든 게시물은 macOS Monterey 12.0.1 버전 기준으로 작성하였습니다.
부스트캠프 AI Tech 3기를 위한 Pre-Course 를 토대로 작성하였습니다.

Groupby
기존의 데이터에서 같은 종류의 데이터끼리(Index) 묶어준다. by SPLIT
함수를 적용한다. by APPLY
묶어서 하나의 결과를 보여준다. by COMBINE


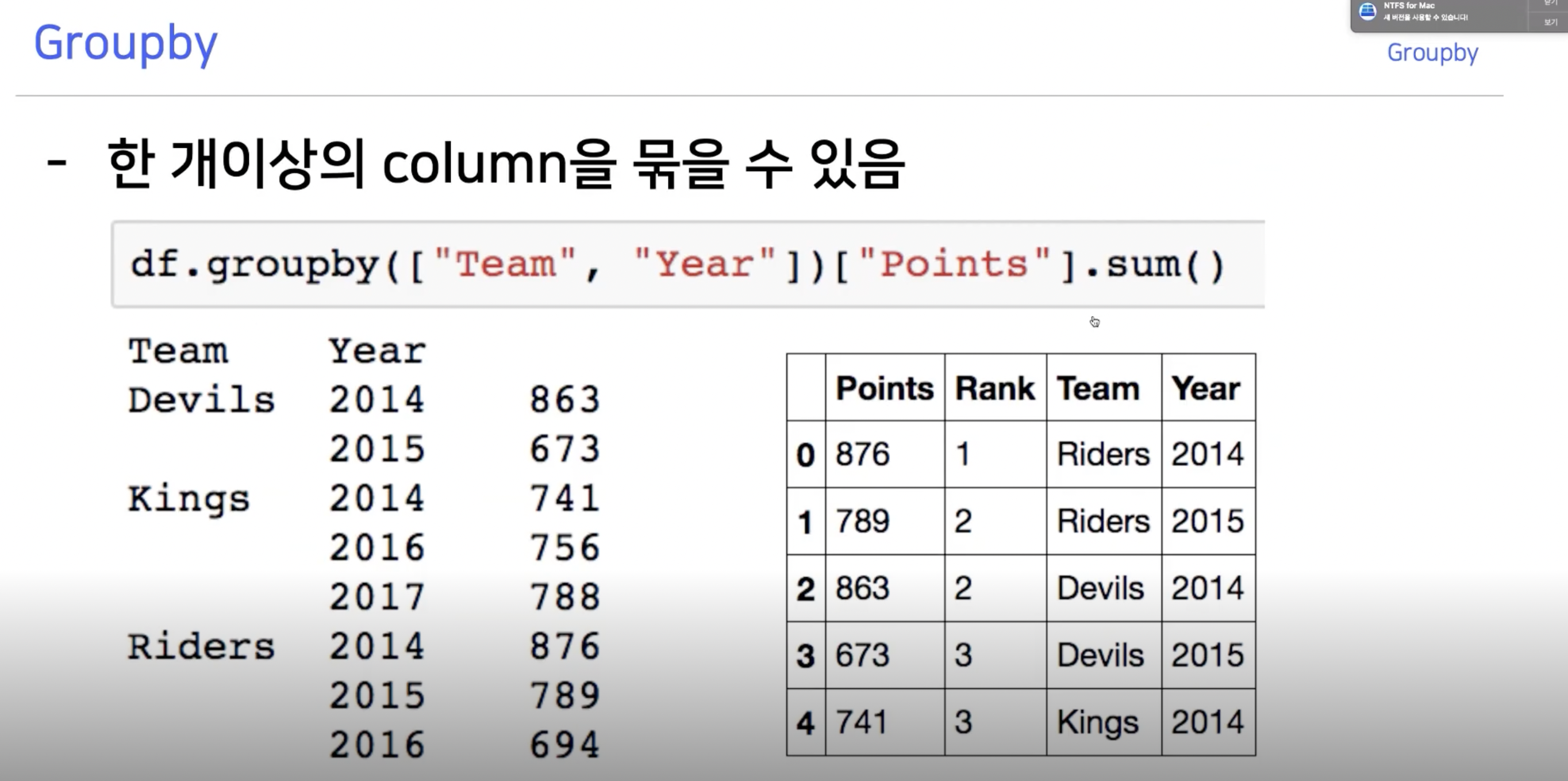
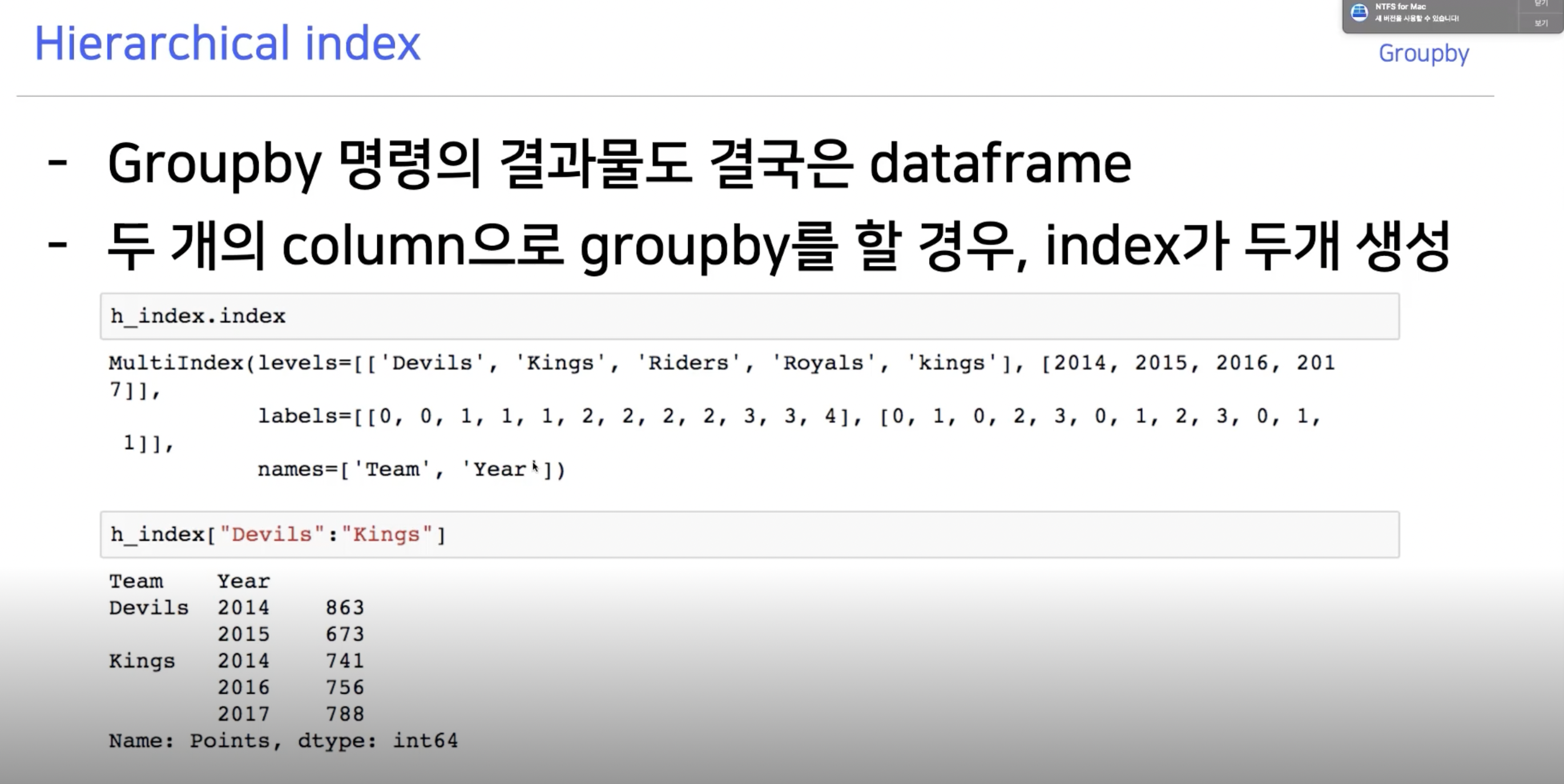
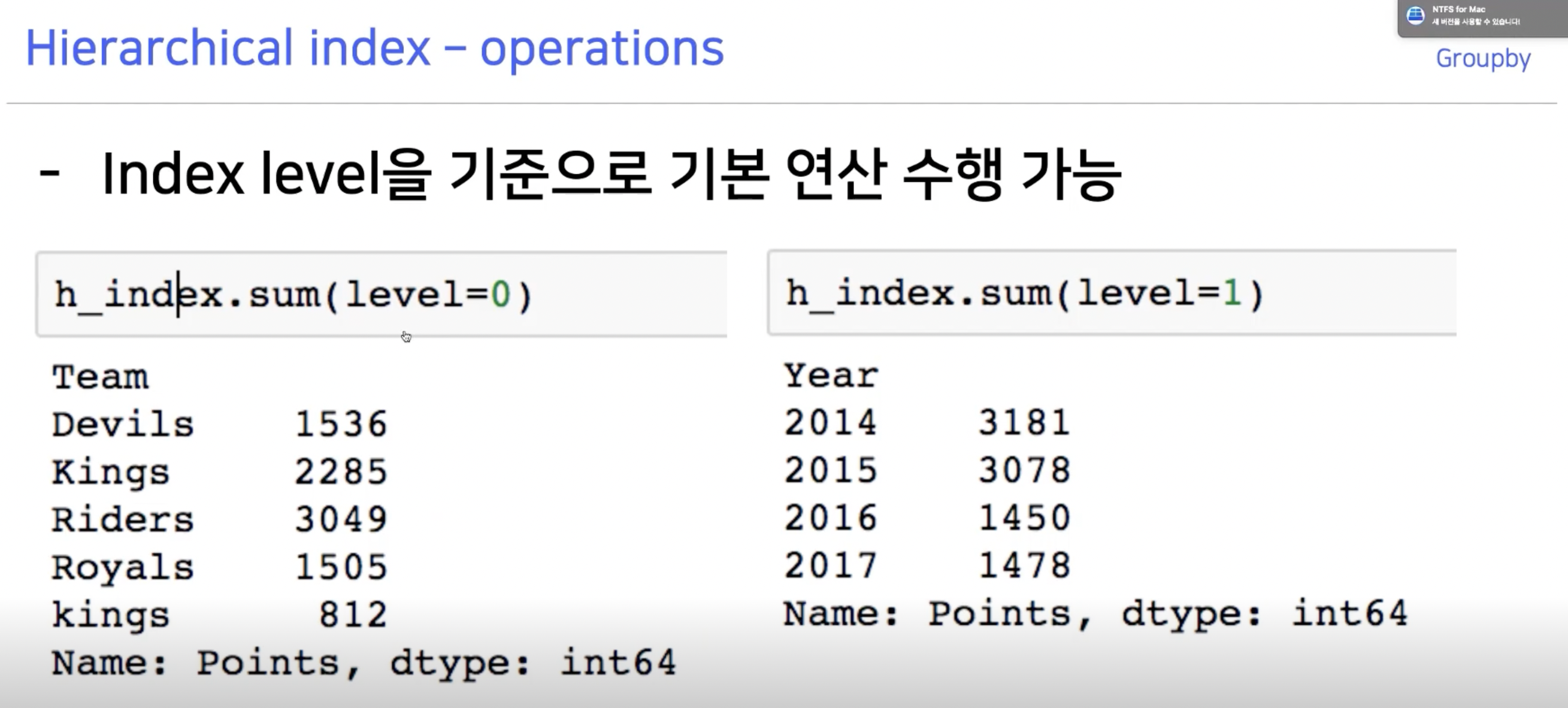
Groupby의 기준 column을 두 개 이상 잡으면 Hierarchical Index가 만들어진다.
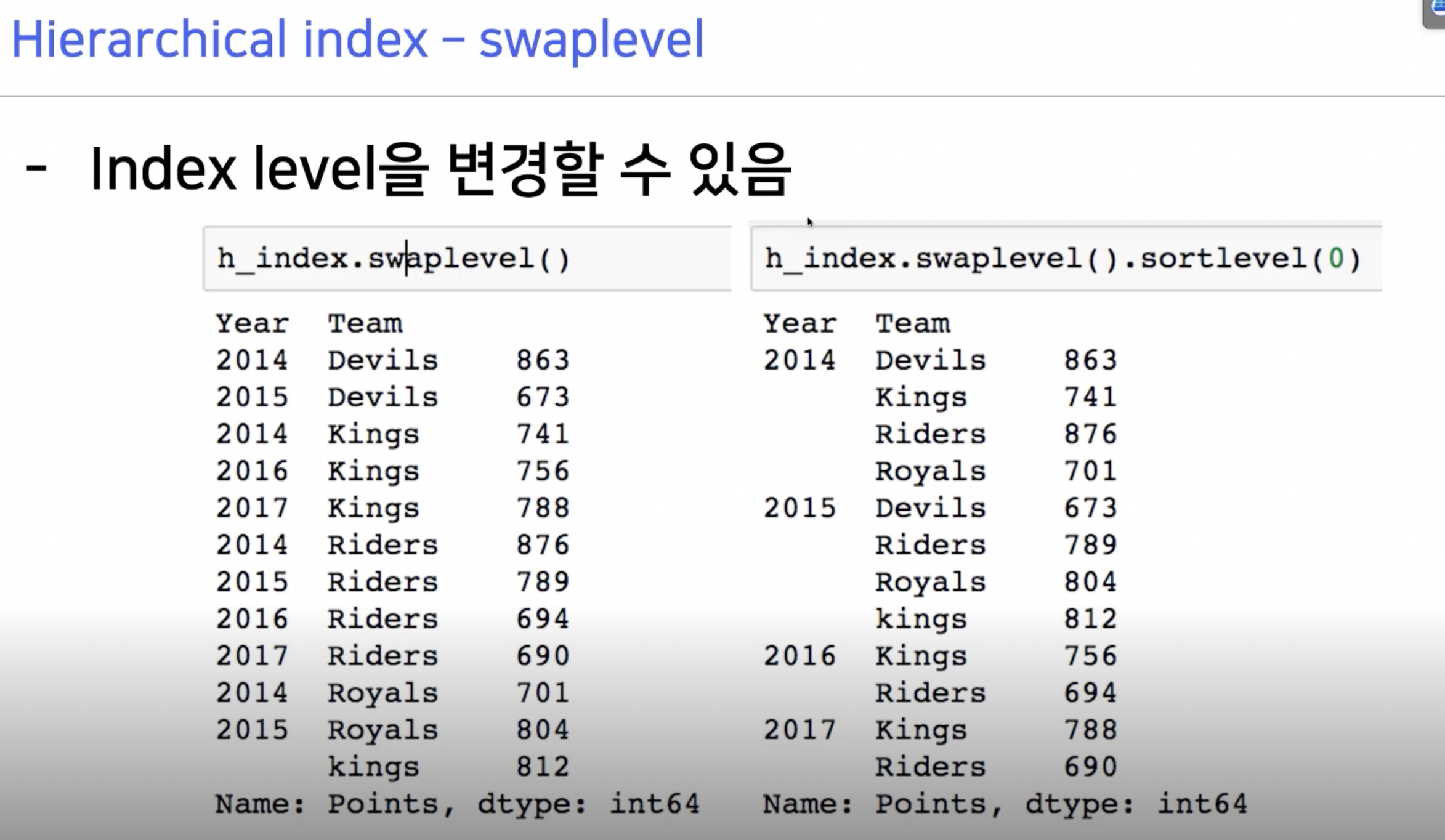
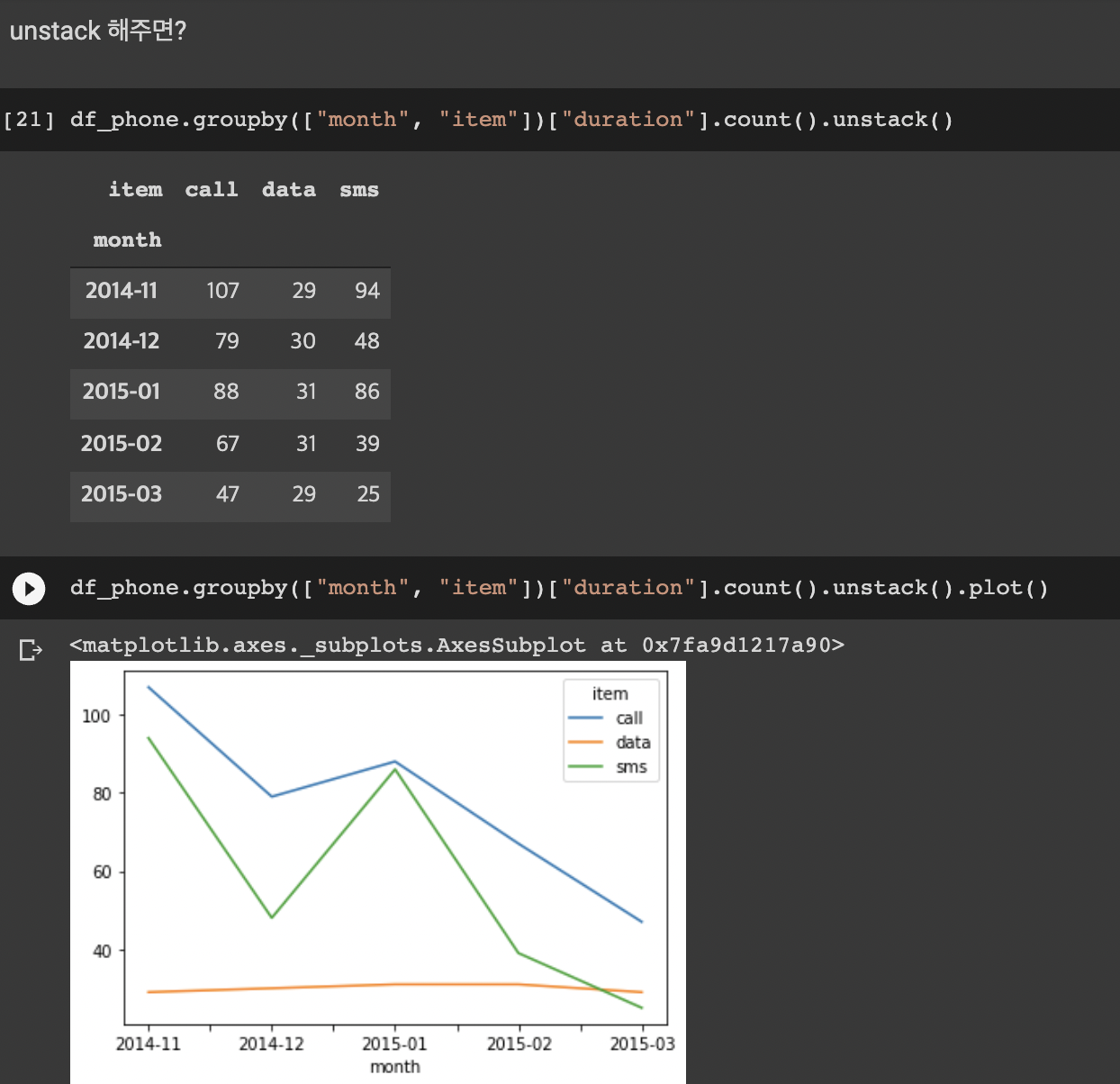
이때 사용할 수 있는 것중에 하나가 unstack 이다. 데이터를 matrix로 풀어준다.
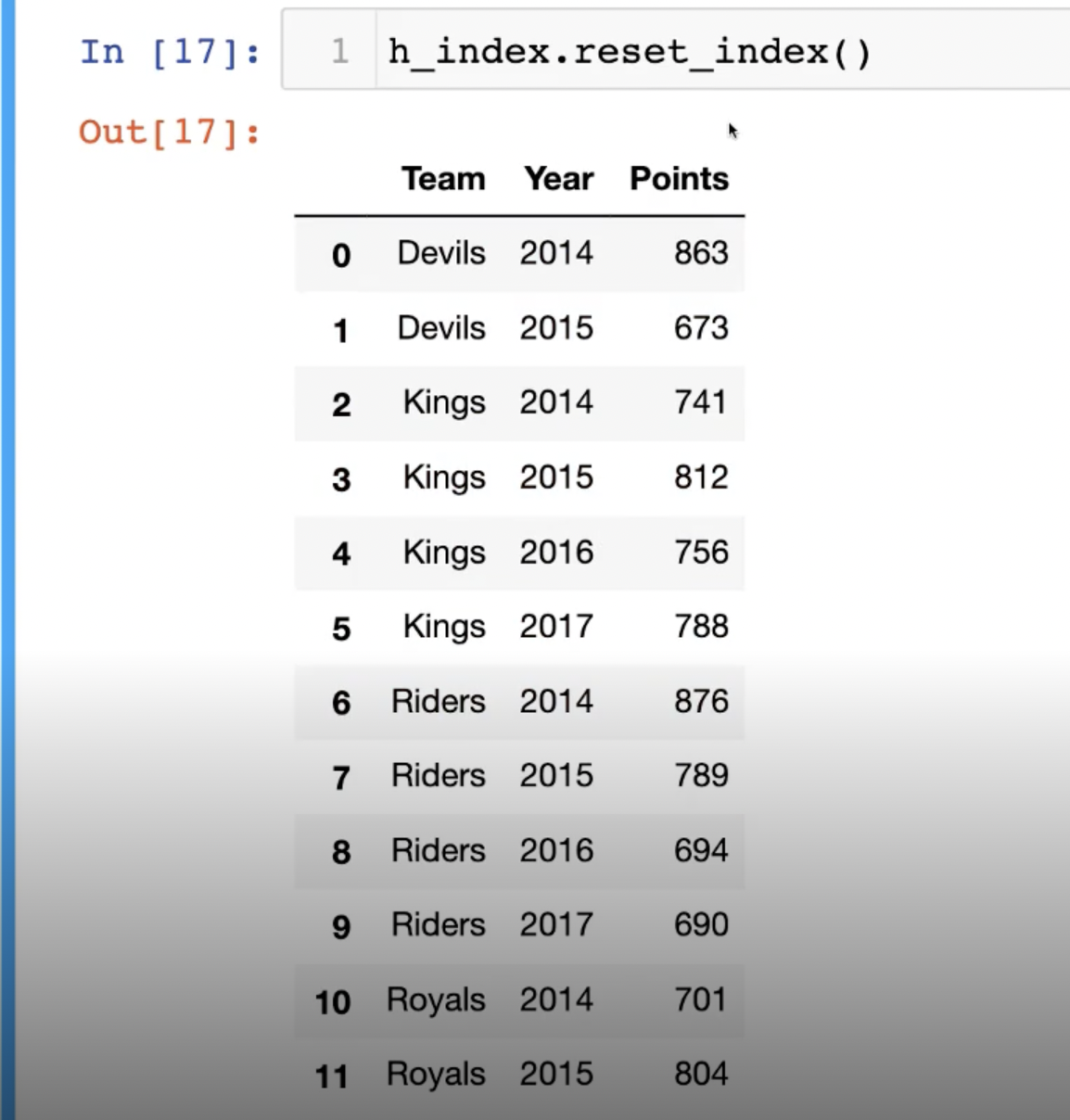
또, Multi Index로 묶여있을 때 사용할 수 있는 것이 reset_index()다.

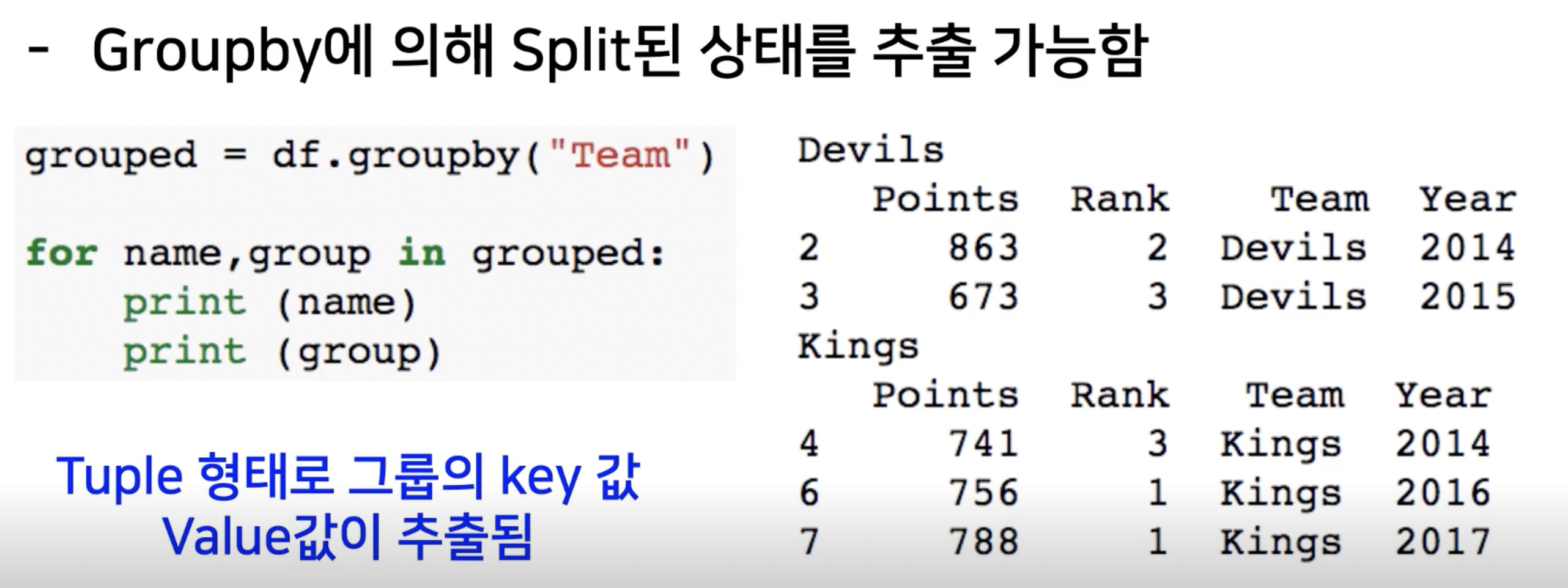
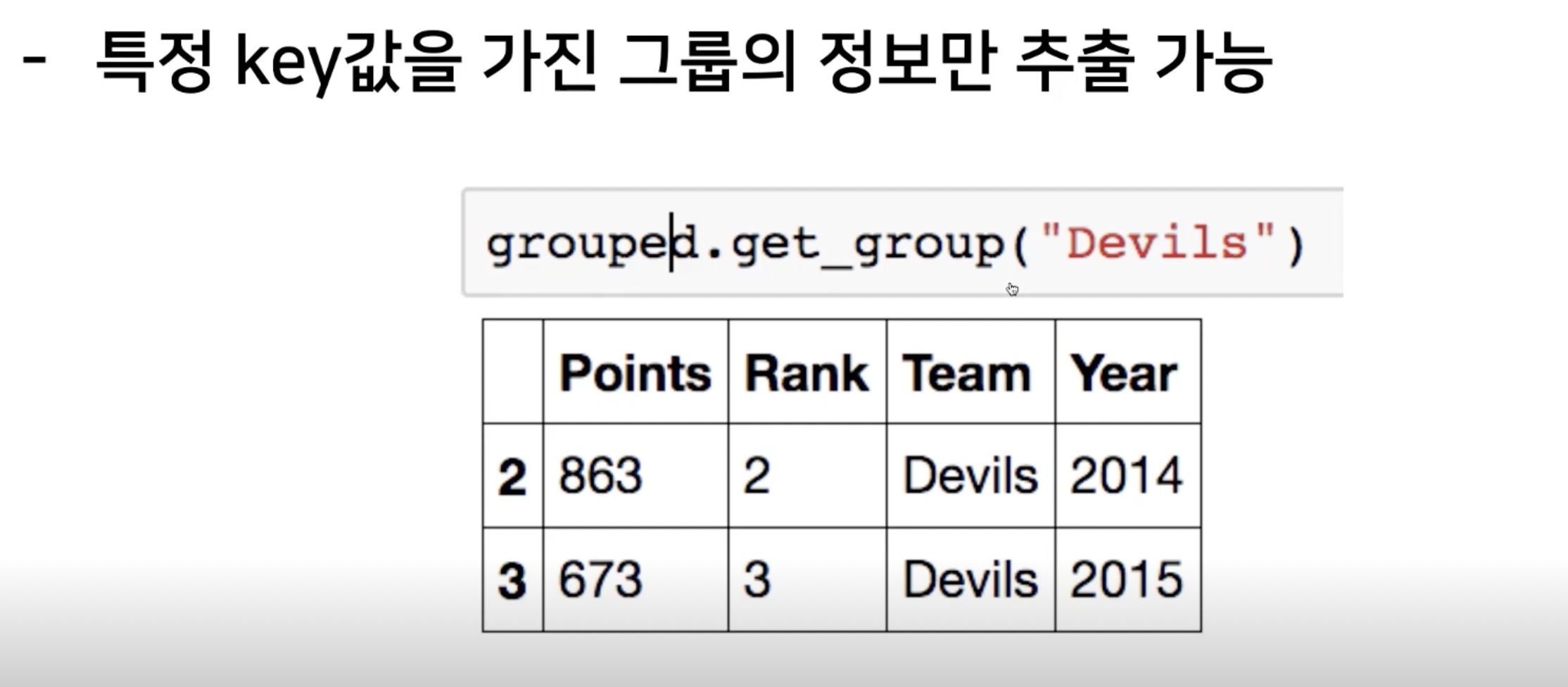
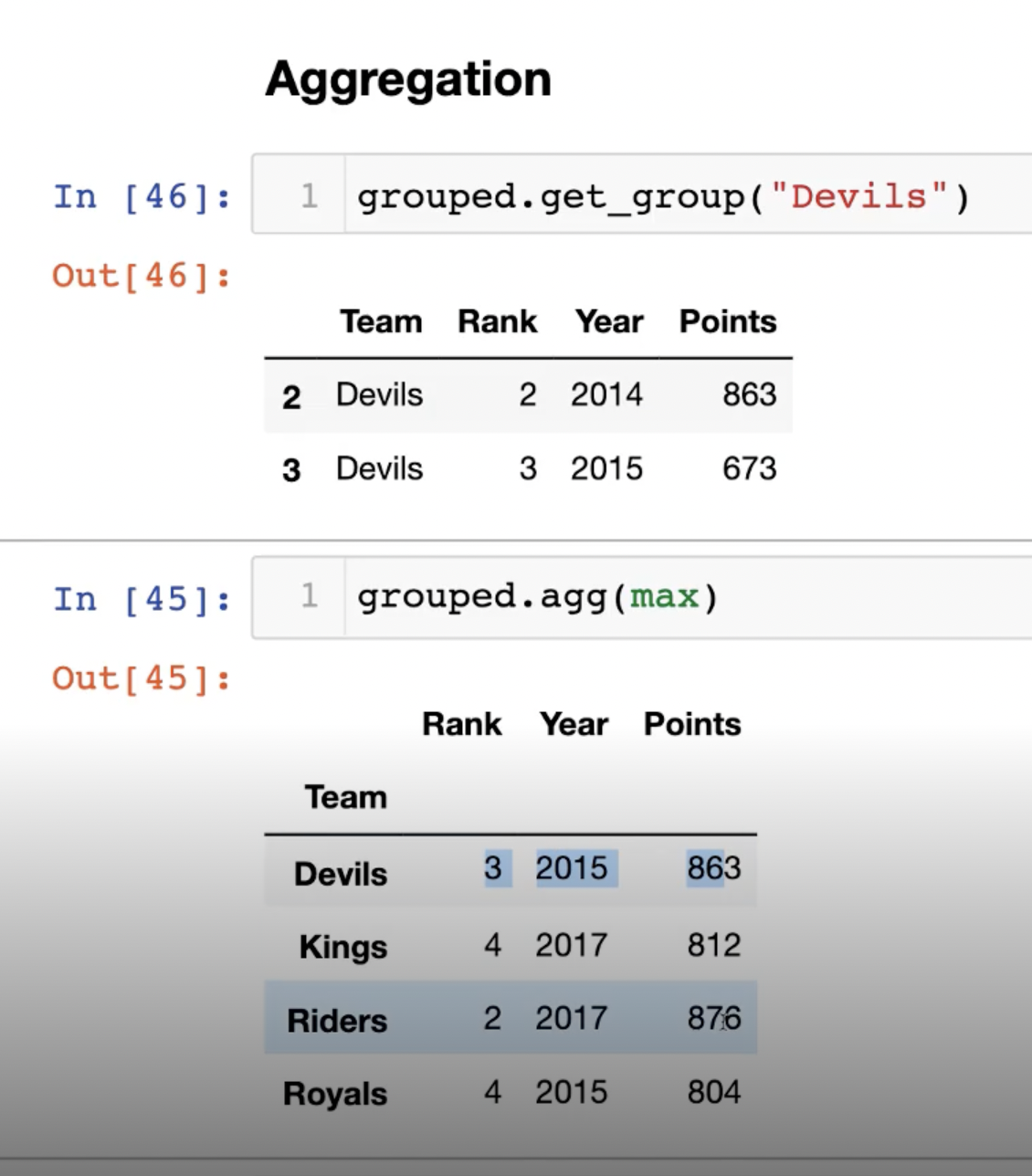
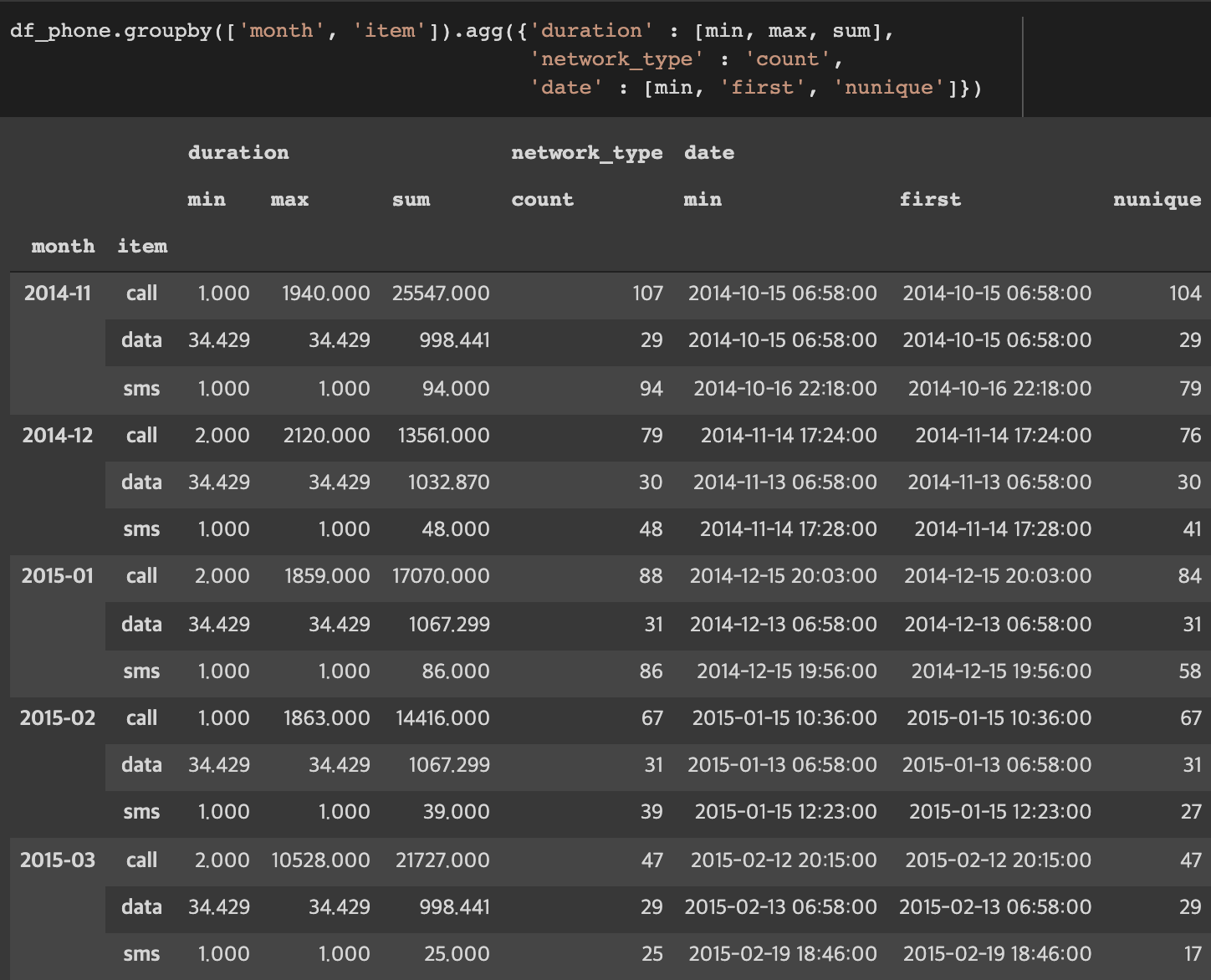
groupby로 만든 grouped 상태에서 적용할 수 있는 세 가지 apply가 있다.

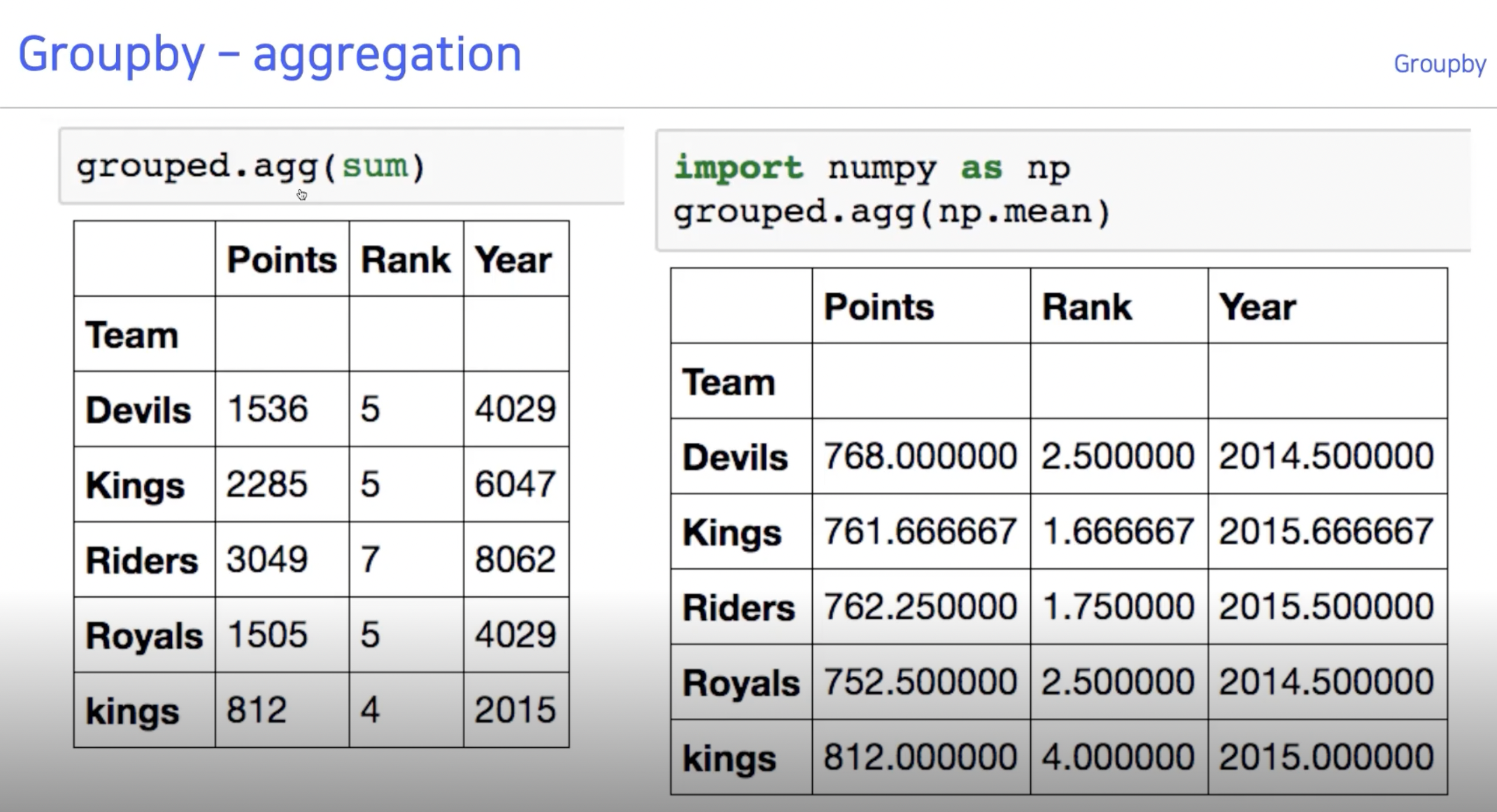
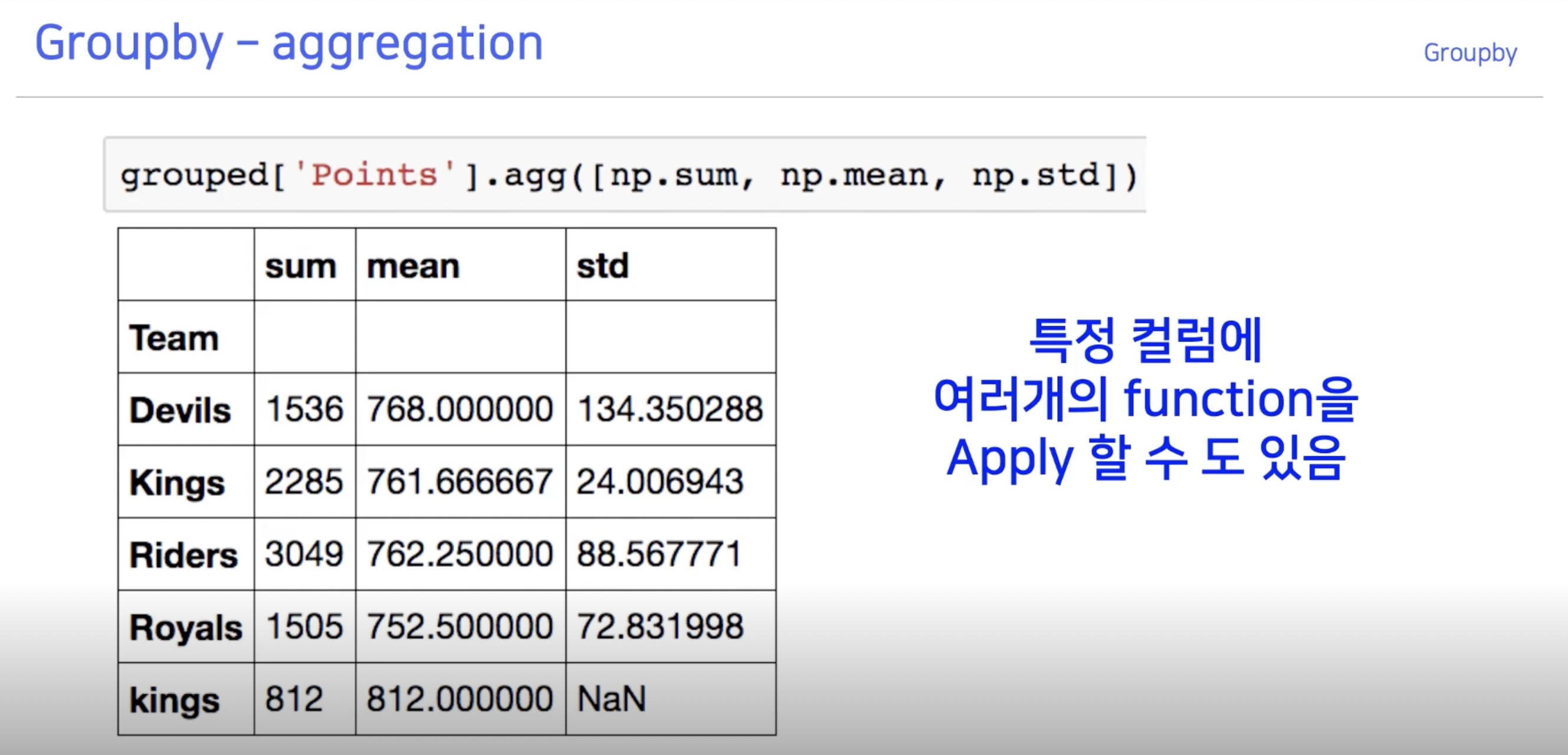
헷갈리지 말아야 할 것은 아래와 같은 상황이다.
grouped = df.groupby("Teams") 로 얻은 grouped에서
grouped.agg(max)를 이용하면 각 column 별로 Maximum 값이 나오는 것이지,
한 row에 함께 위치한 데이터가 나오는 것이 아니다.
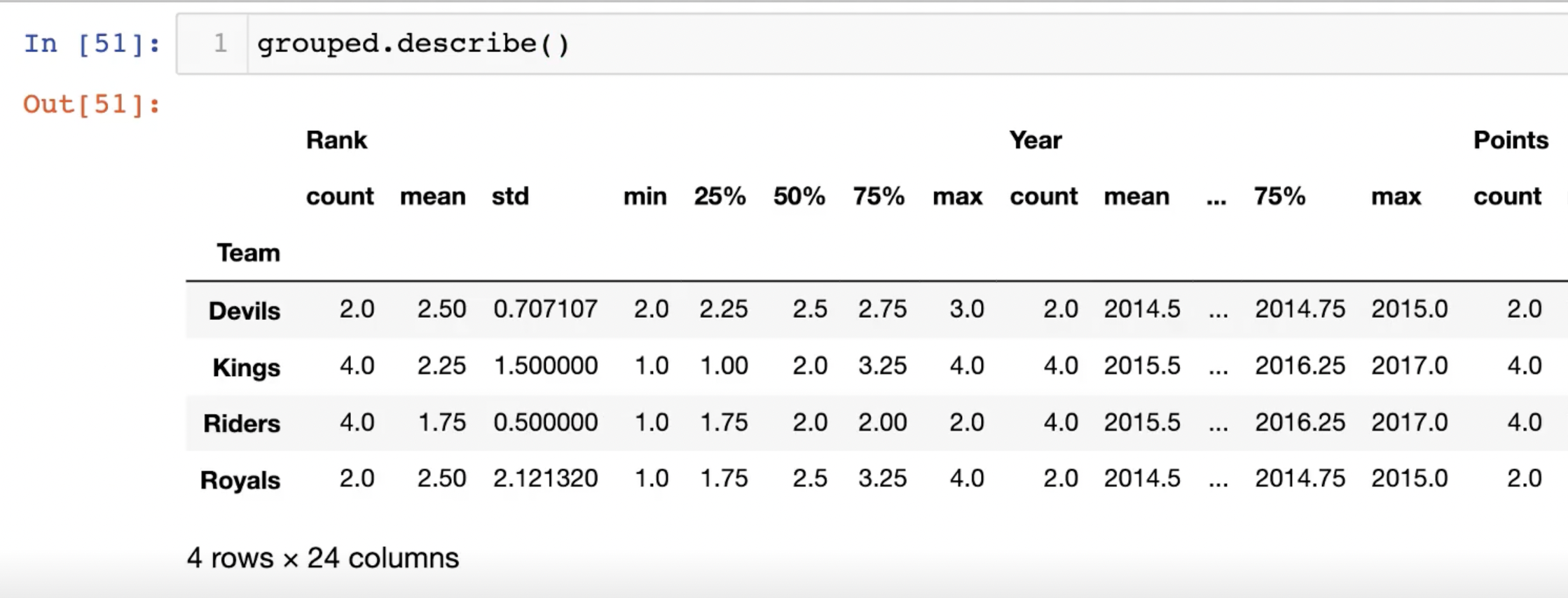
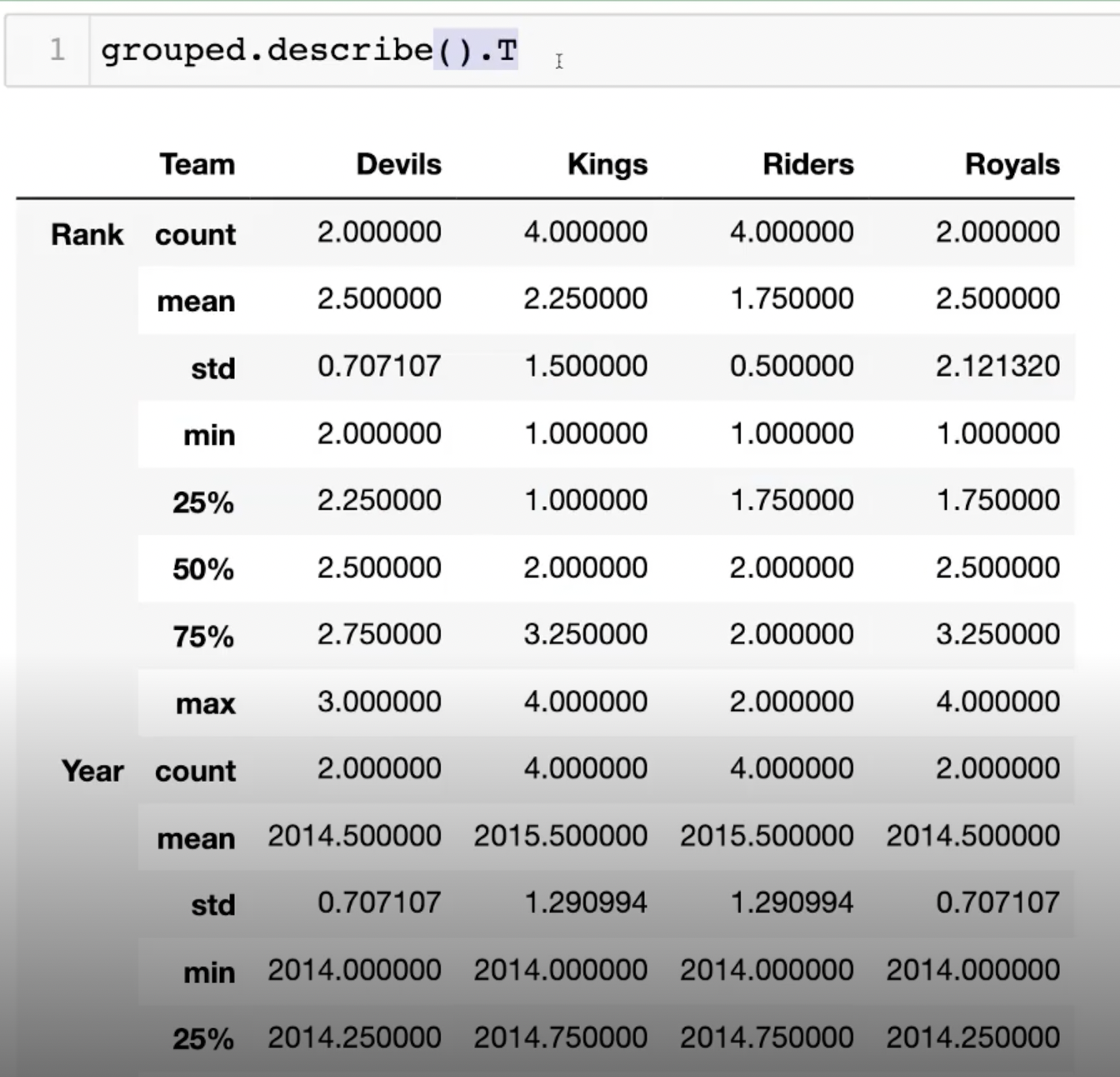
앞서 언급했던 것처럼 grouped.describe()가 보기에 불편하다면
grouped.describe().T와 같이 전치 행렬을 활용해보자.

transformation은 예시를 들어 이해하면 좋다.
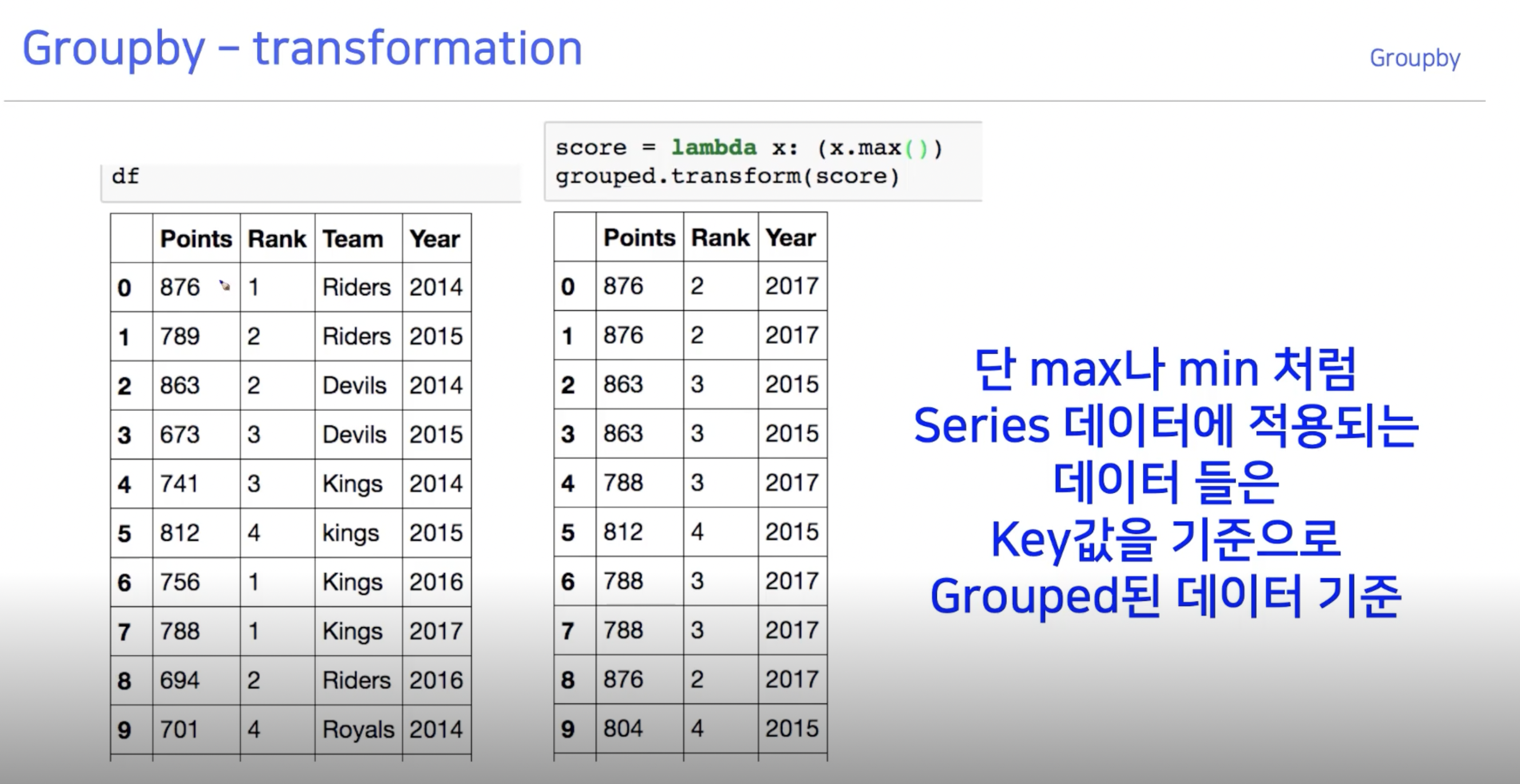
lambda x : (x.max())를 grouped 데이터에 대해 적용하는 것이다.
즉, Team "Riders"인 애들 중에 그 Maximum Points가 876이고,
Maximum Rank가 2이며, Maximum Year은 테이블에 없으나 2017이었던것 !
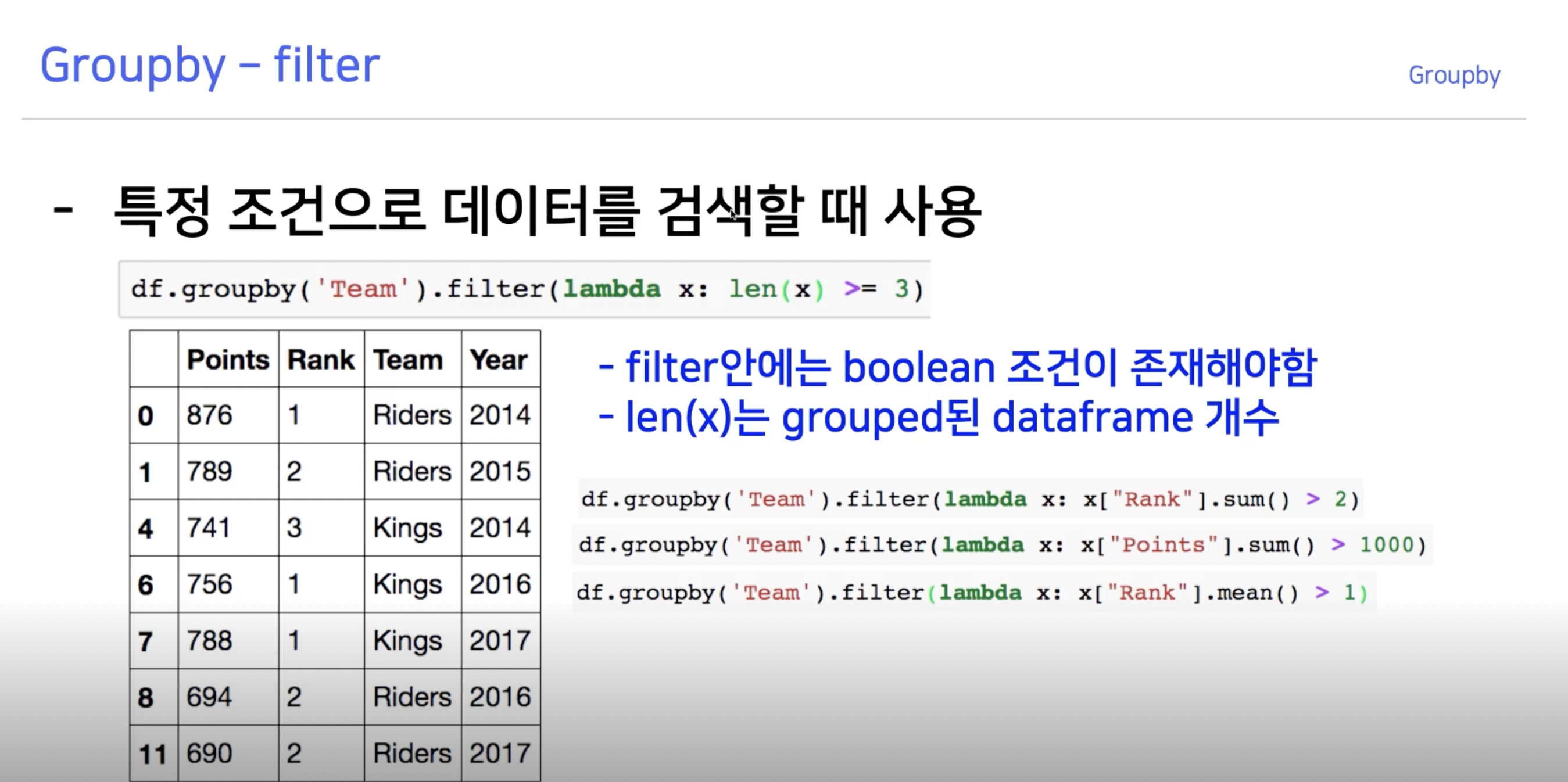

df.groupby("Team").filter(lambda x : len(x) >= 3) 을 예로 들어보자.
Team을 기준으로 grouped 된 상황에서 그 타입의 객체가 3개 이상인 애들만 꺼내
오른쪽 그림과 같은 상황이므로 "Riders"와 "Kings"만 나오는 것이 맞다.
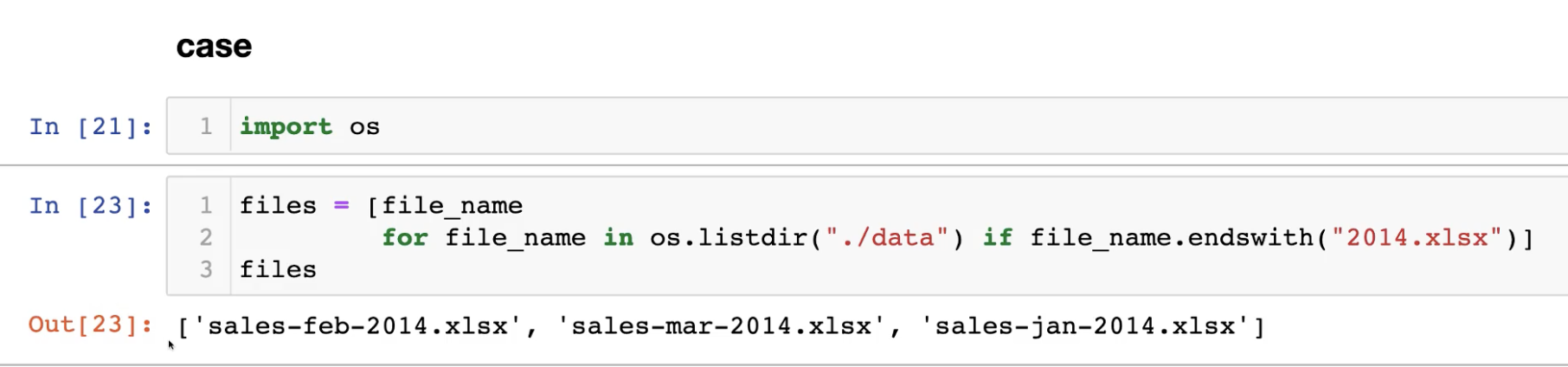
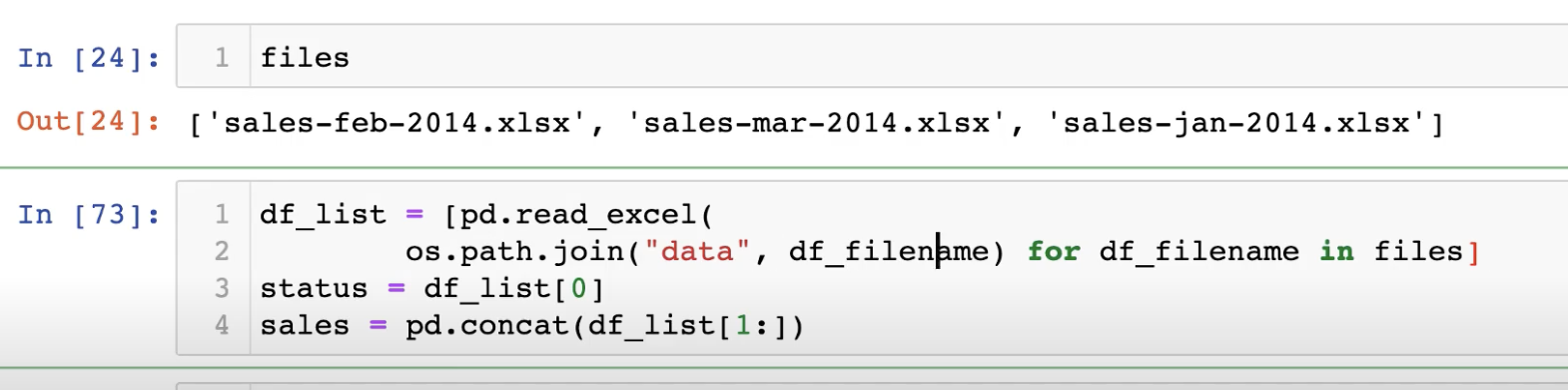
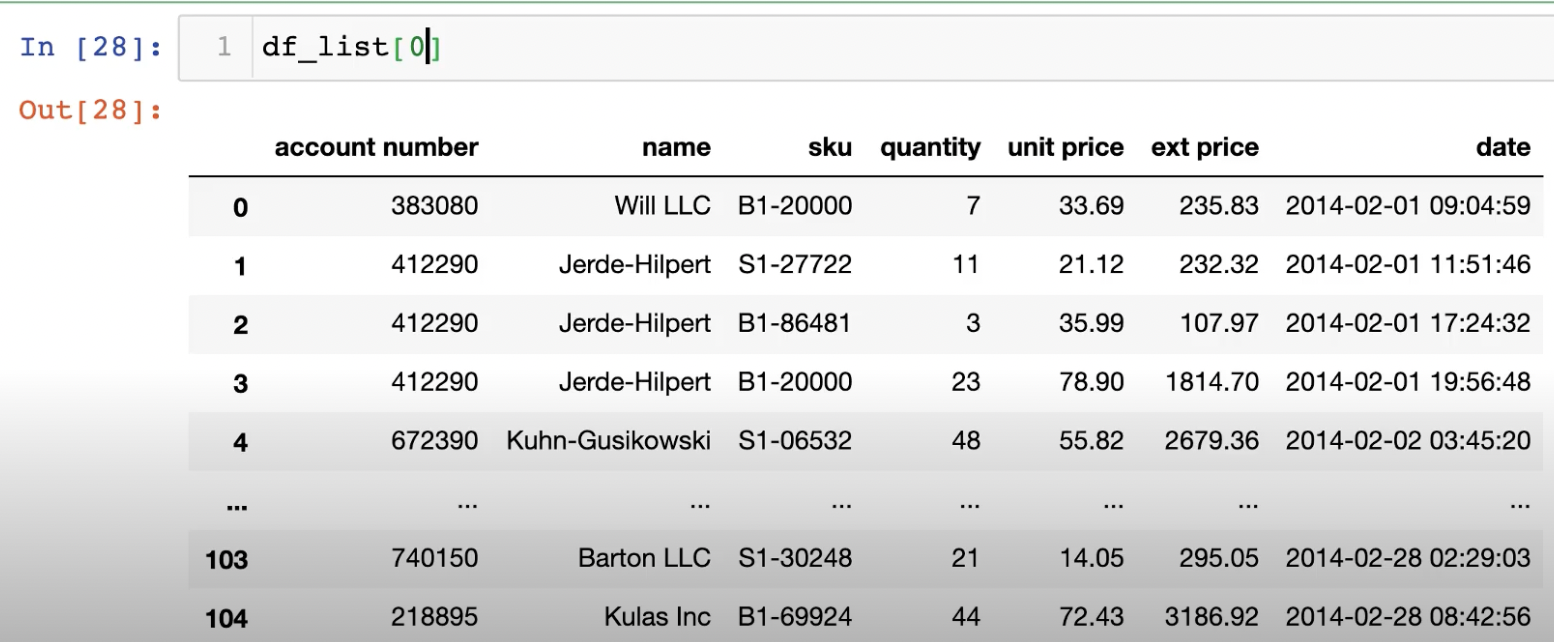
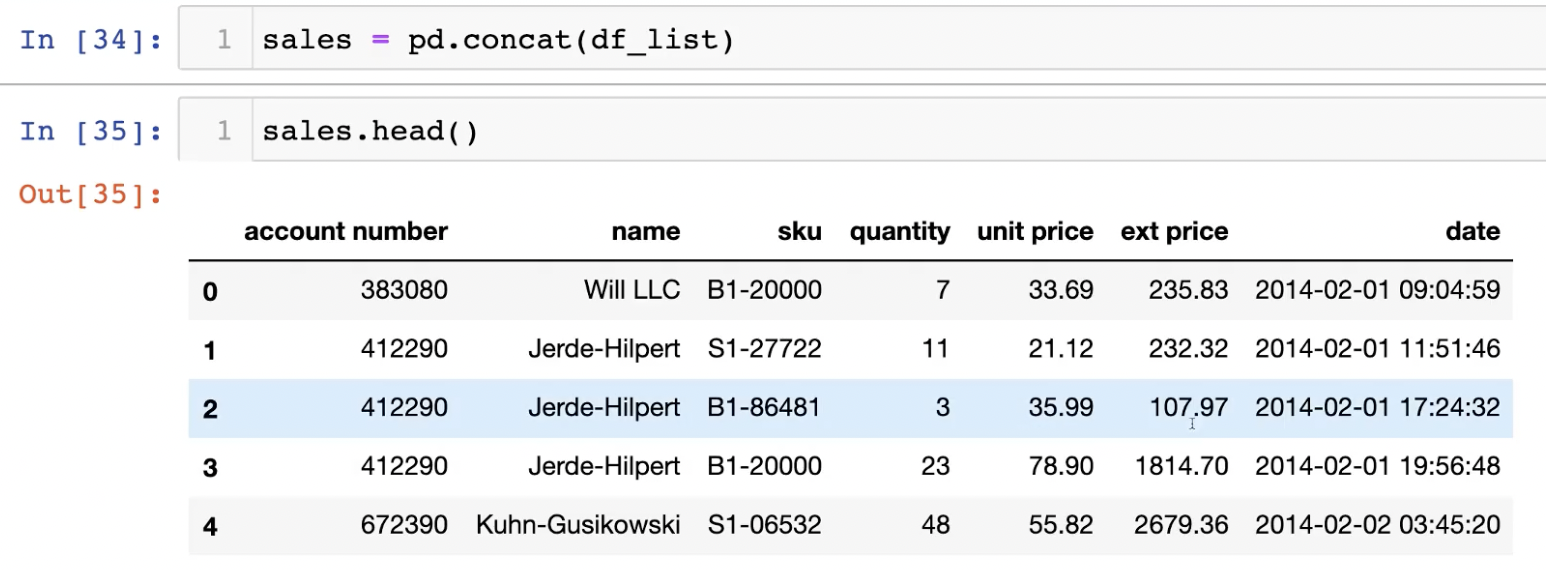
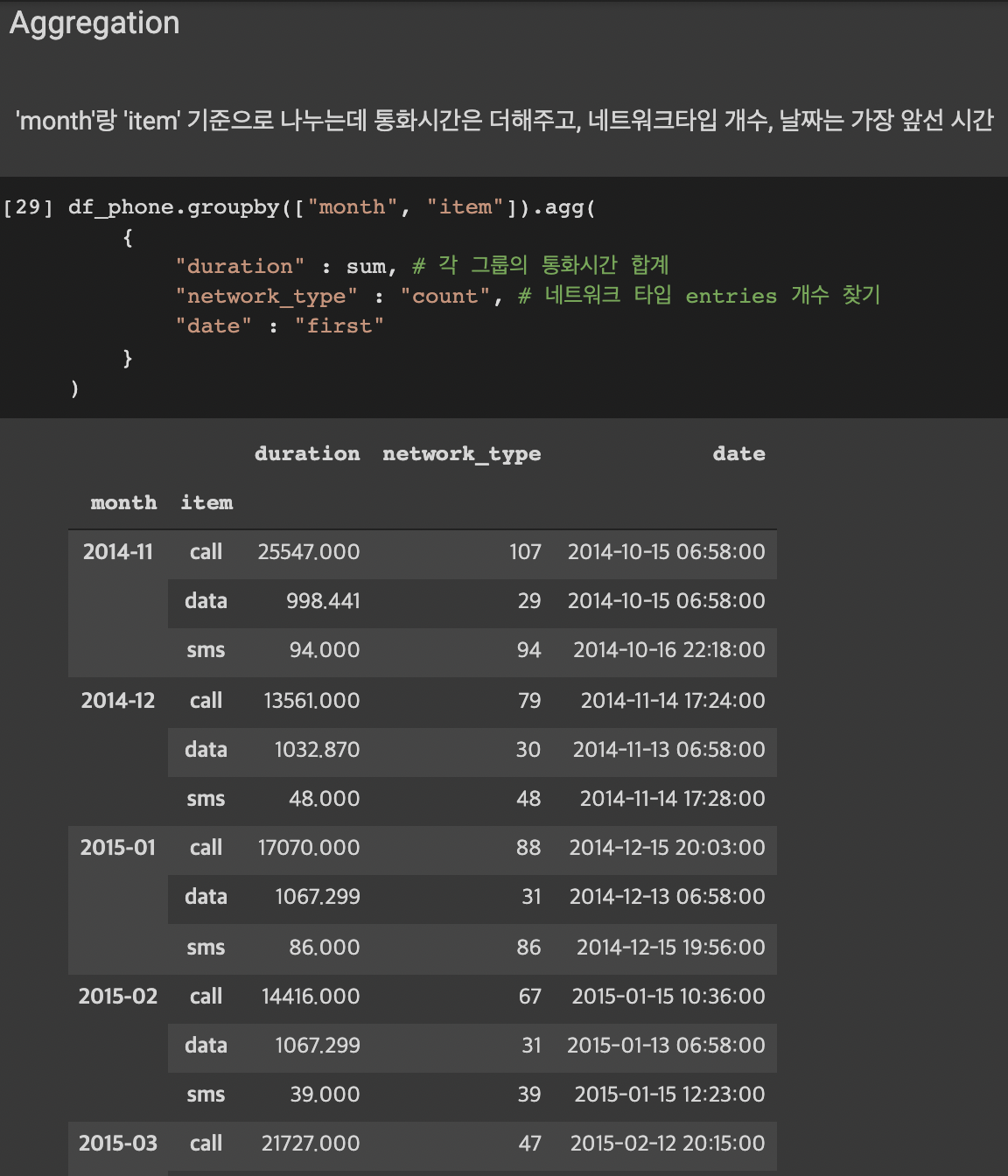
지금까지 배운 내용을 토대로 실제 데이터와 함께 Case Study를 진행해보자.
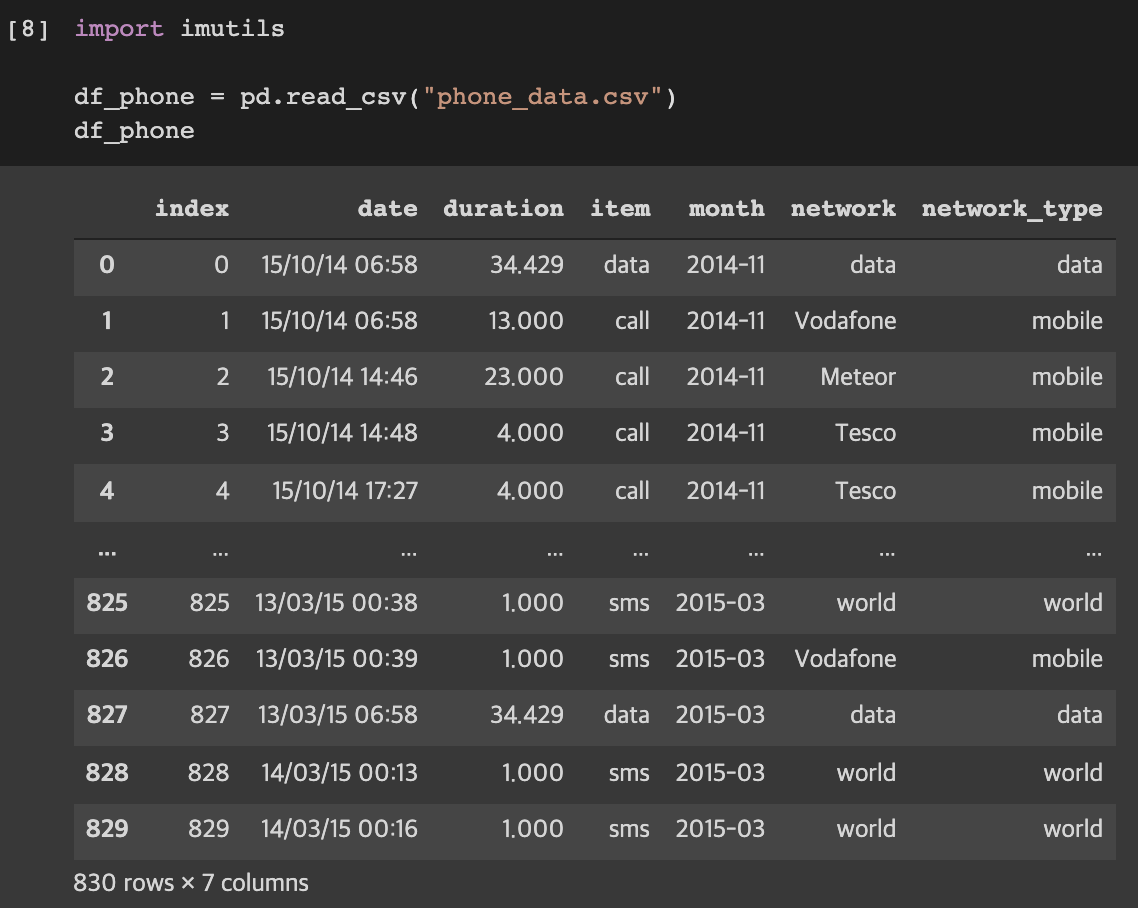
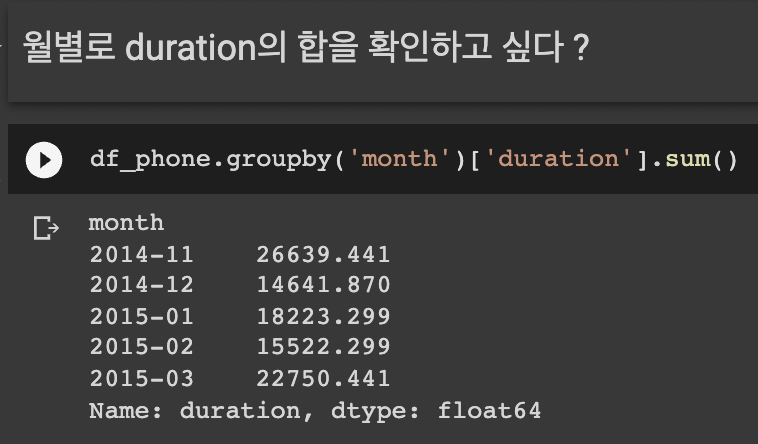
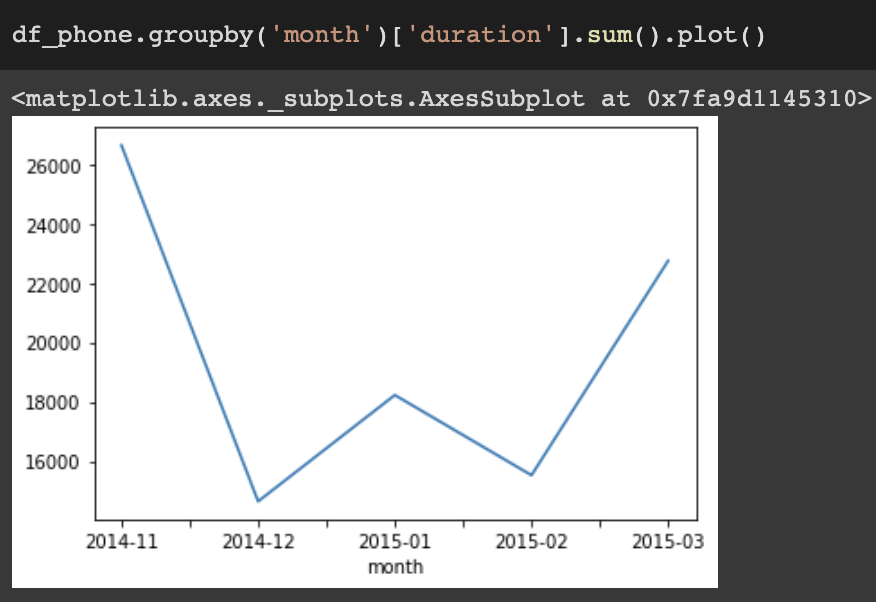
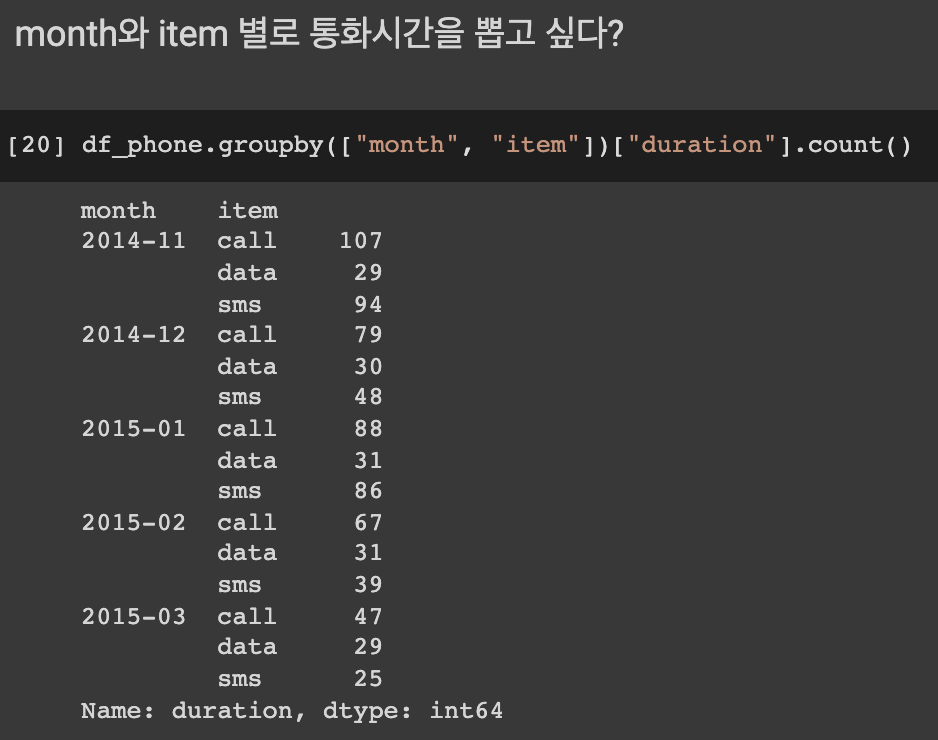
시간과 데이터 종류가 정리된 통화량 데이터다.
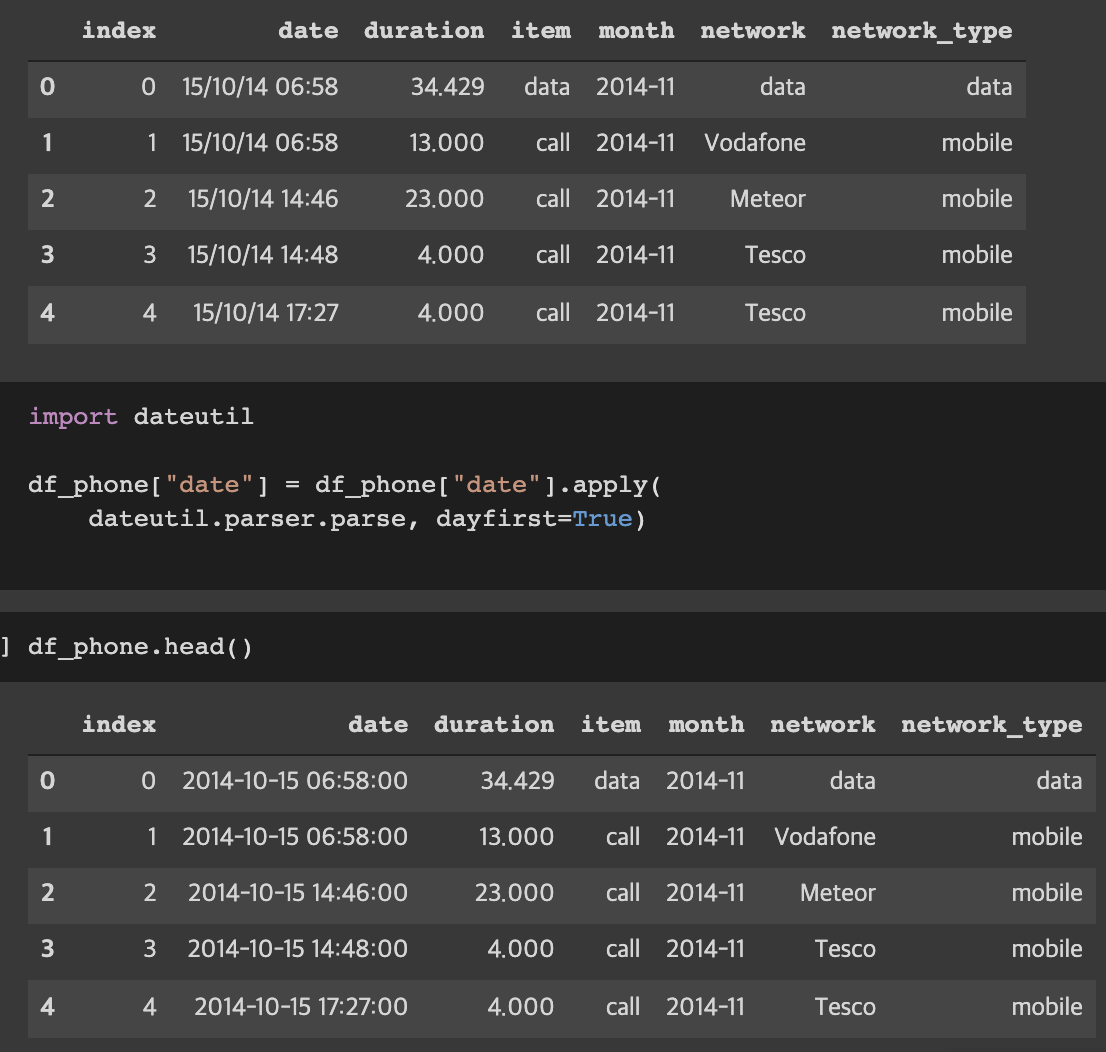
가장 먼저 dateutil 모듈을 활용하여 날짜 데이터를 string -> 날짜 데이터로 바꾸자.
dateutil.parser.parse 는 문자 형태를 날짜로 바꿔주는 모듈로 apply 시켜주자.
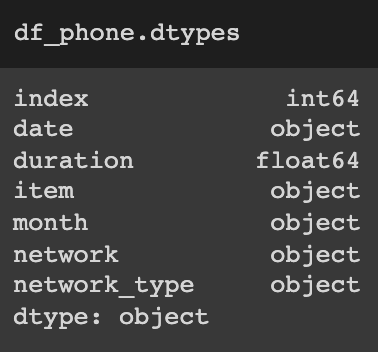
아래는 .add_prefix 메서드 사용하는 방법이다.

Pivot Table & Crosstab

groupby와 unstack을 사용해도 괜찮지만 더 쉬운 방법이 pivot table & crosstab
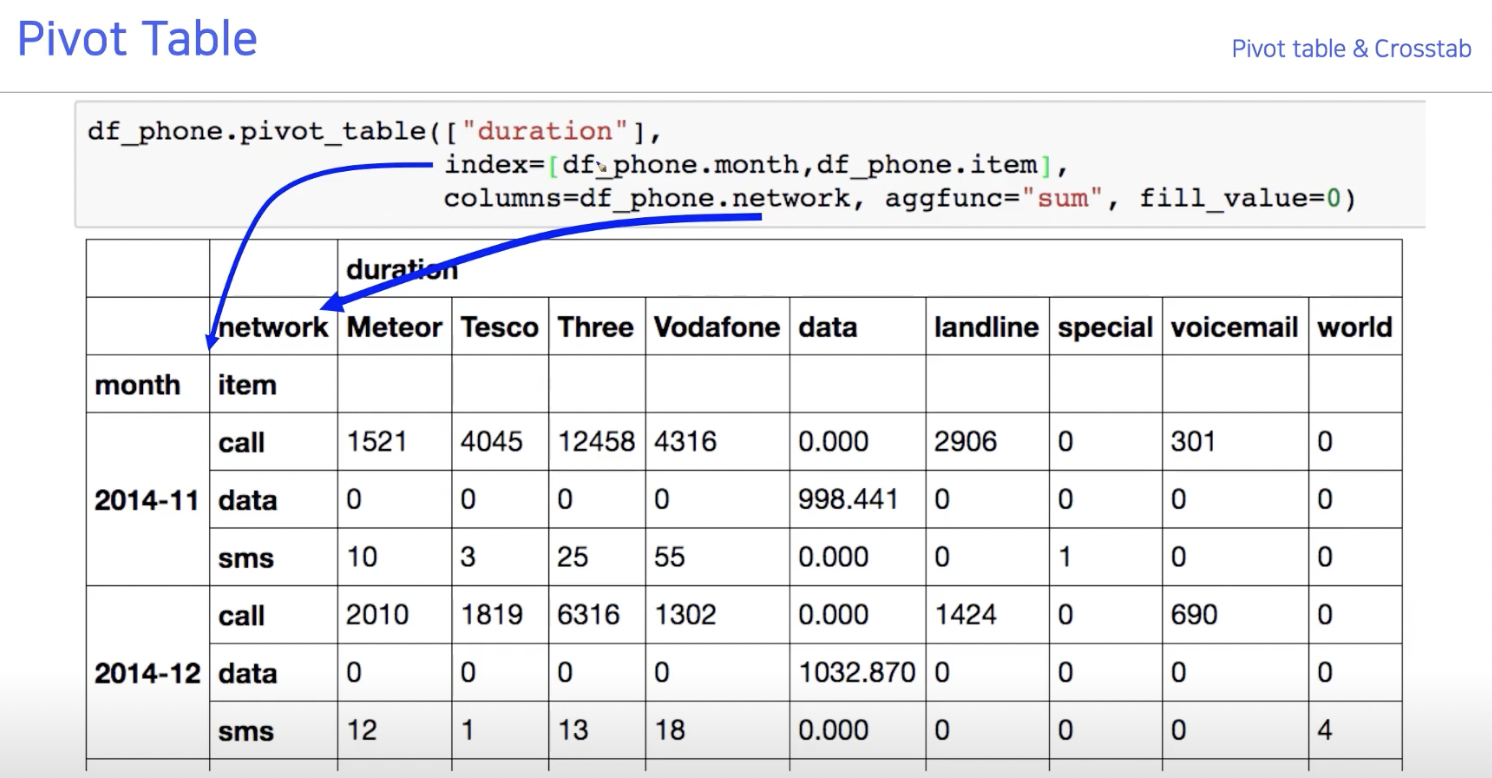
궁금한 대상은 "duration"
나눌 기준이 될 것은 "month" & "item"
column에 넣고 싶은 것은 "network"
진행할 aggregation function은 'sum'
위 pivot table을 groupby를 통해서는 얻을 수 없을까? 아래 코드를 살펴보자.
df_phone.groupby(["month", "item", "network_type"])["duration"].sum().unstack()

거의 동일한데 보통 네트워크 형태의 데이터를 표현할 때 조금 더 편리하다.
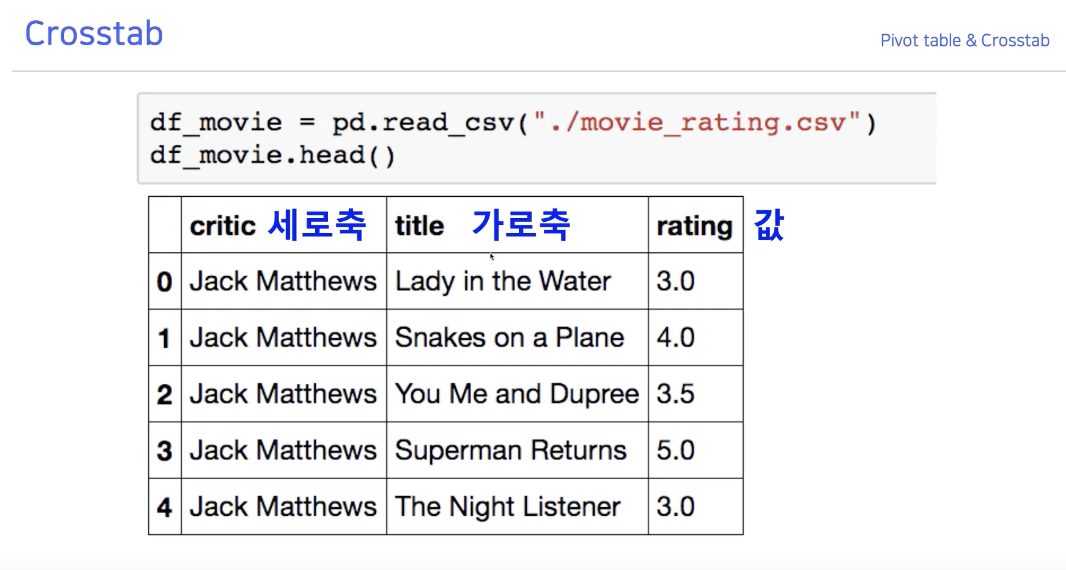
영화 평점 데이터와 유사한데 "어떤 평론가가 어떤 영화에 몇점을 줬다."

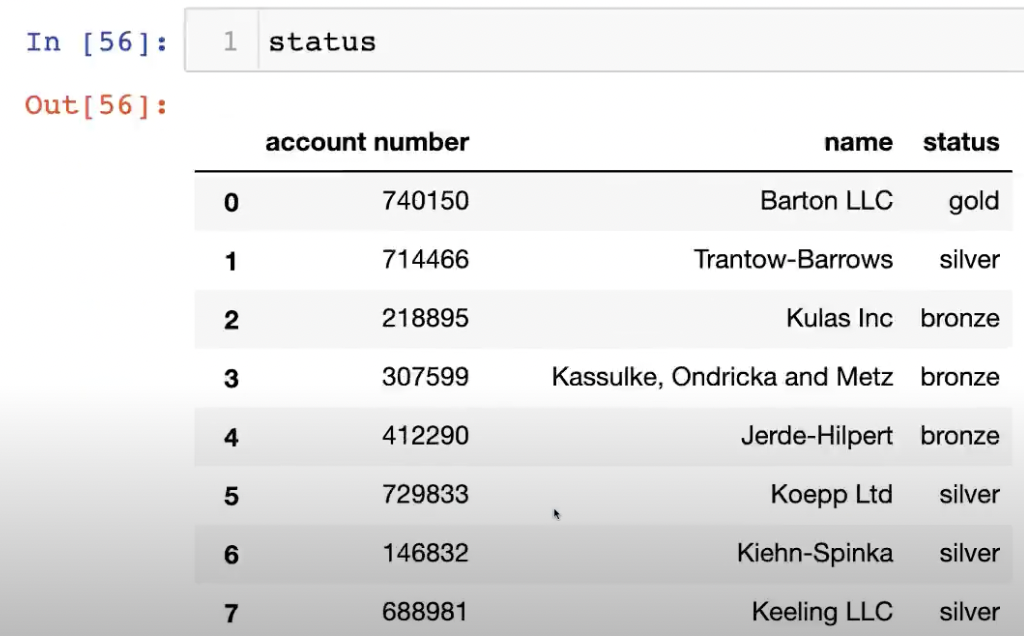
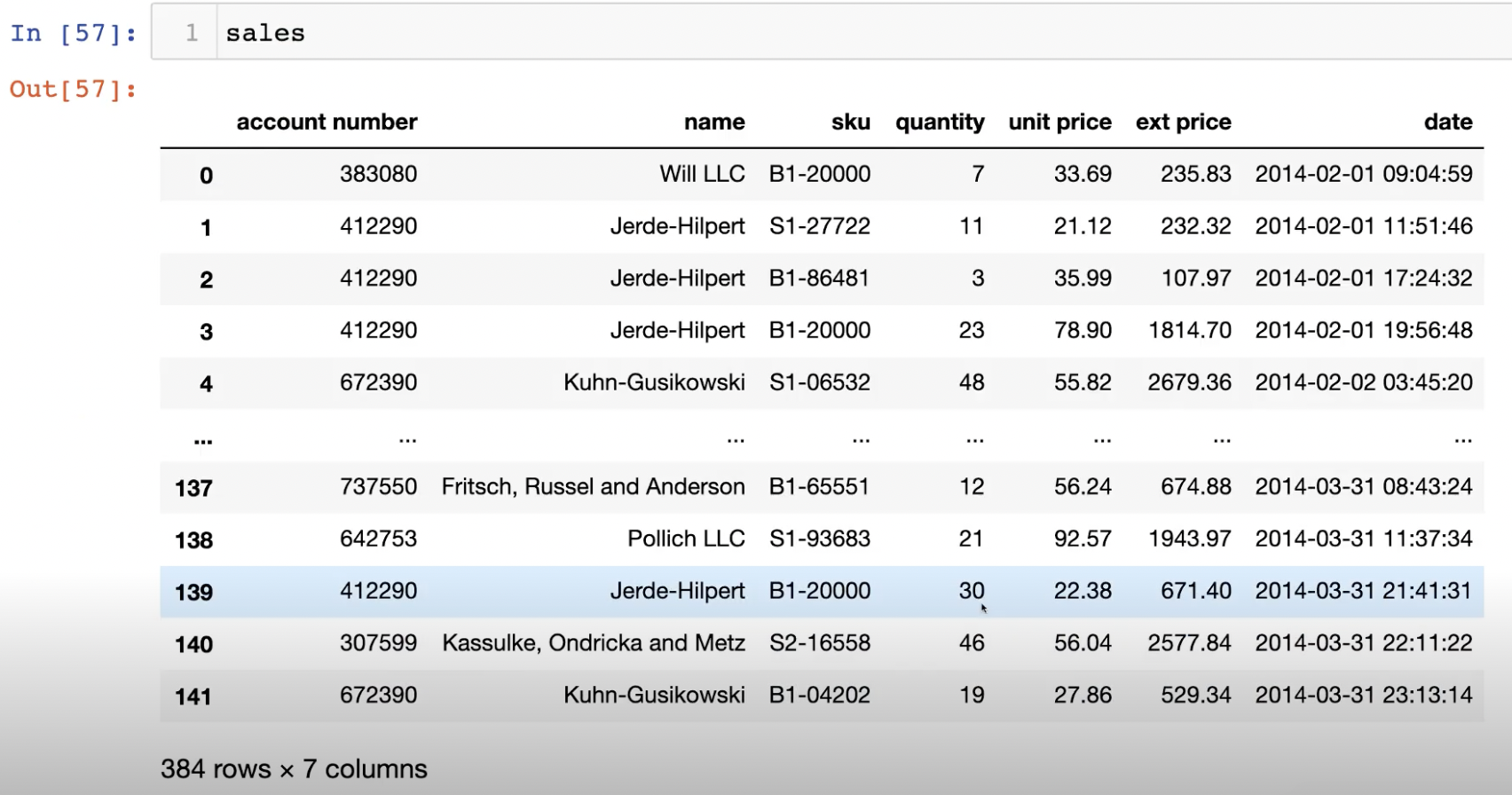
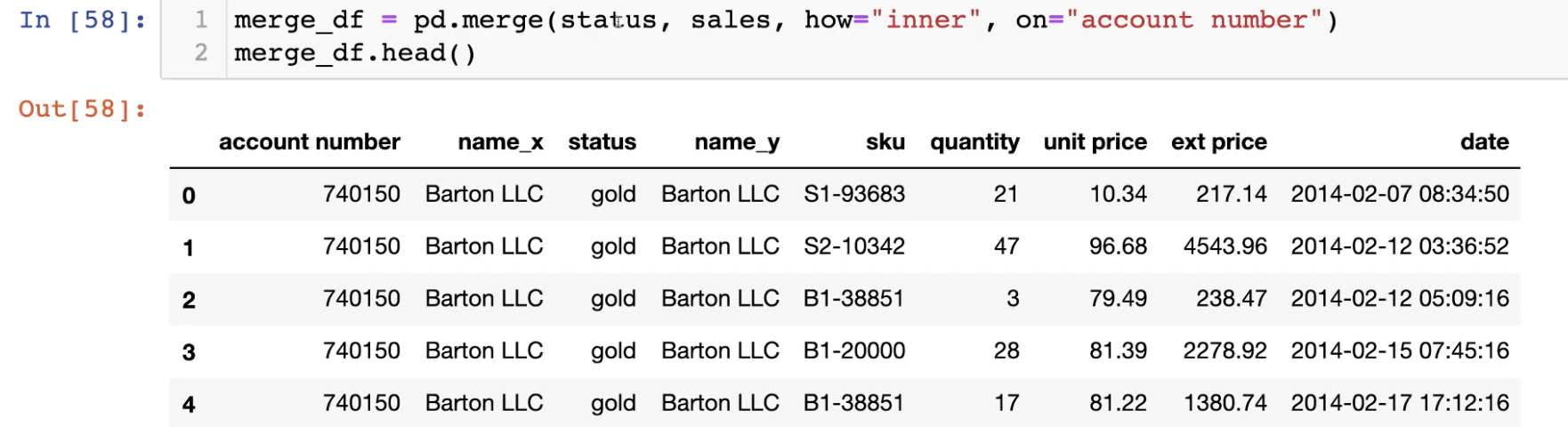
Merge
데이터를 합치고 붙이는 것에 대해 알아보자.
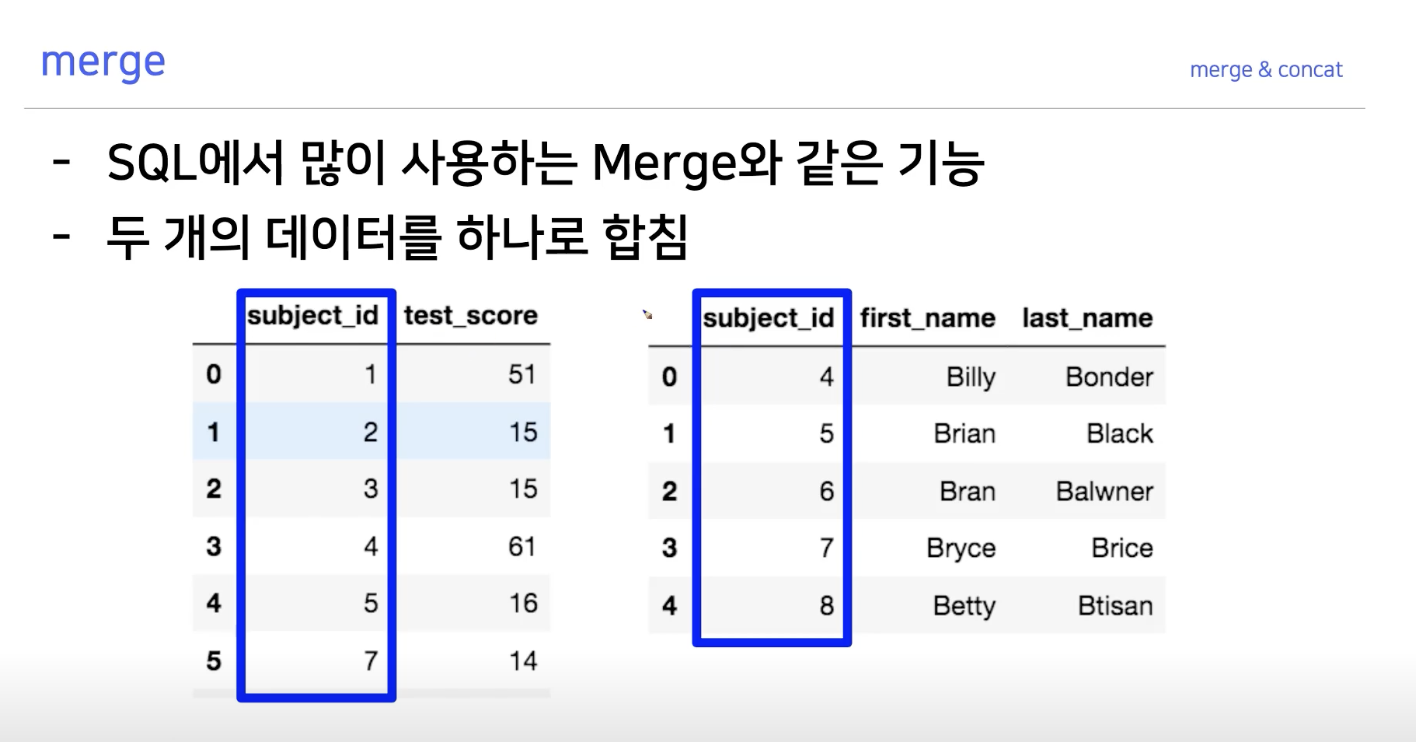
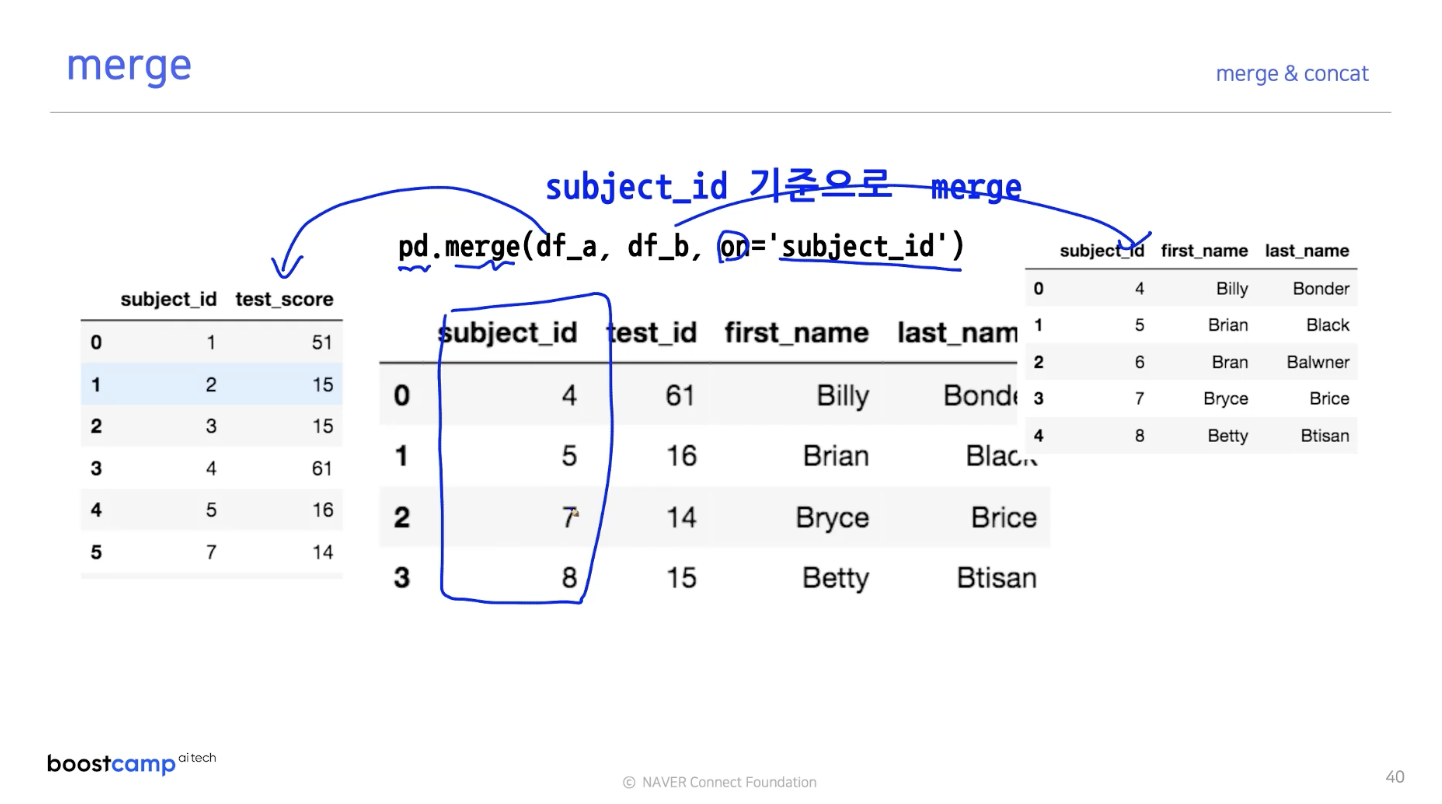
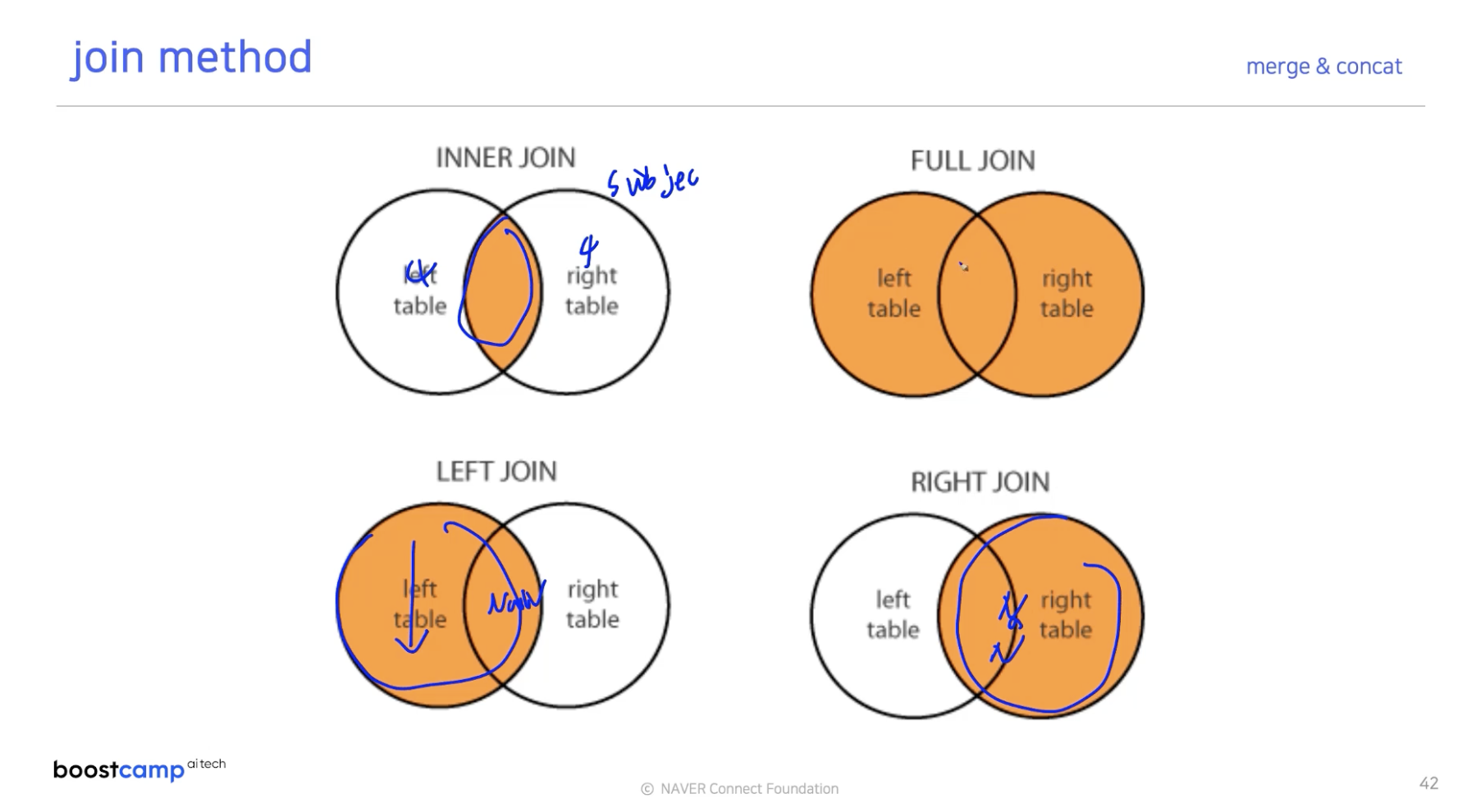
데이터를 대상으로 한 예시로 위의 Join 종류에 대하여 알아보자.
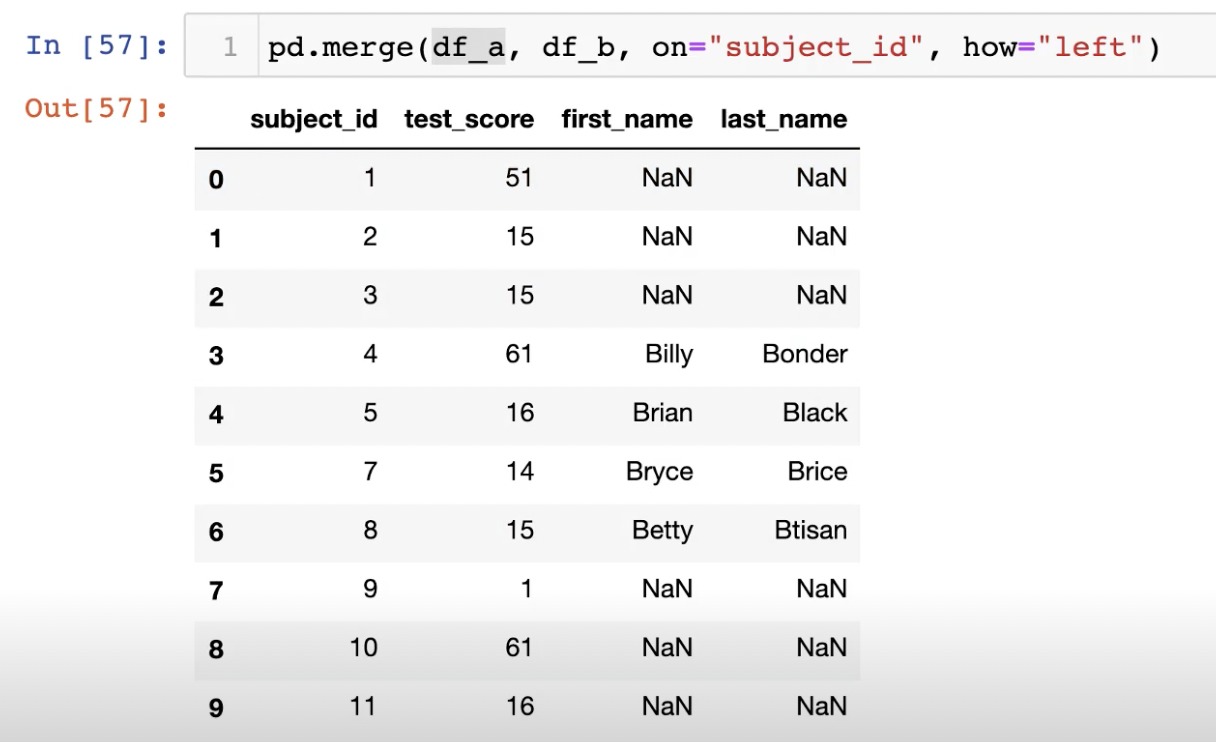
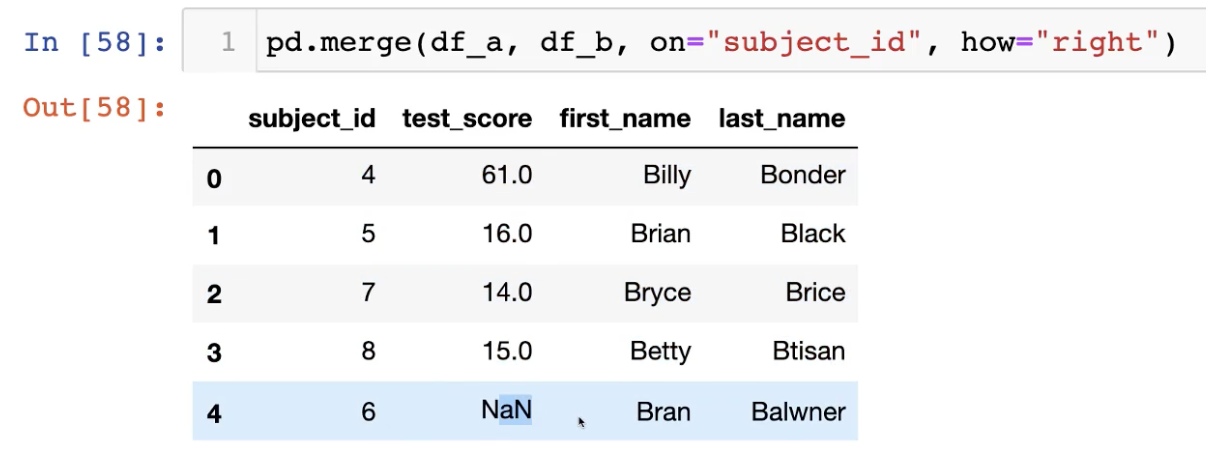
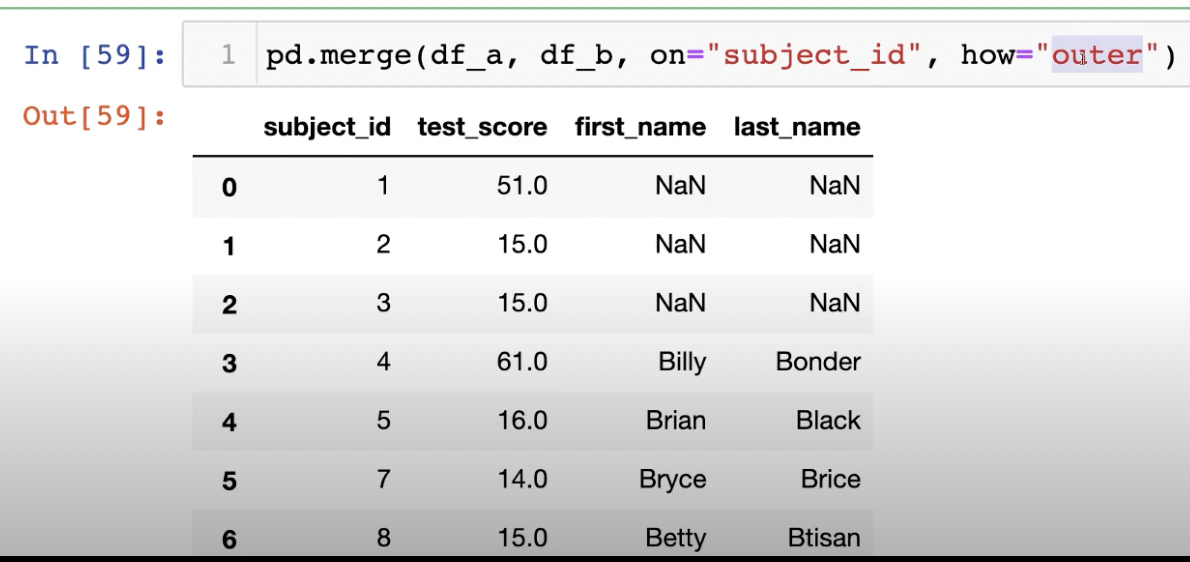
how에 아무것도 적어주지 않으면 inner join 결과를 도출한다.
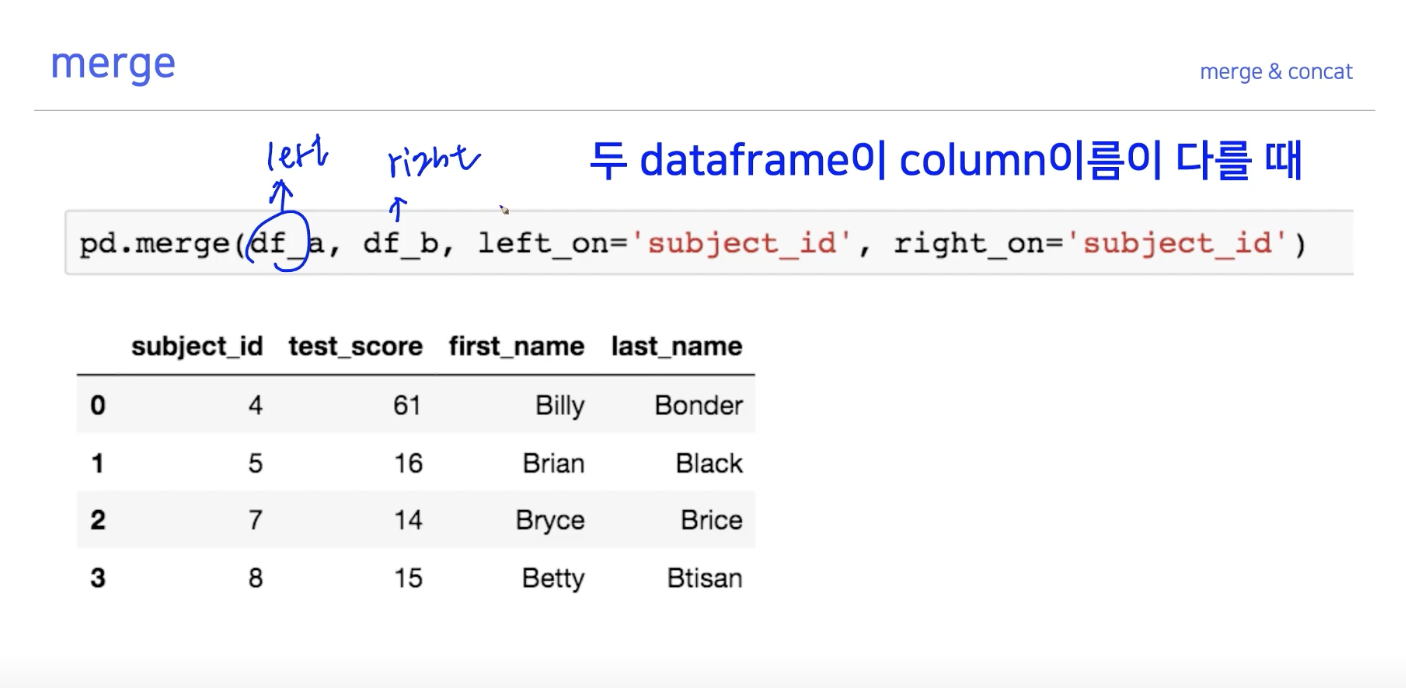
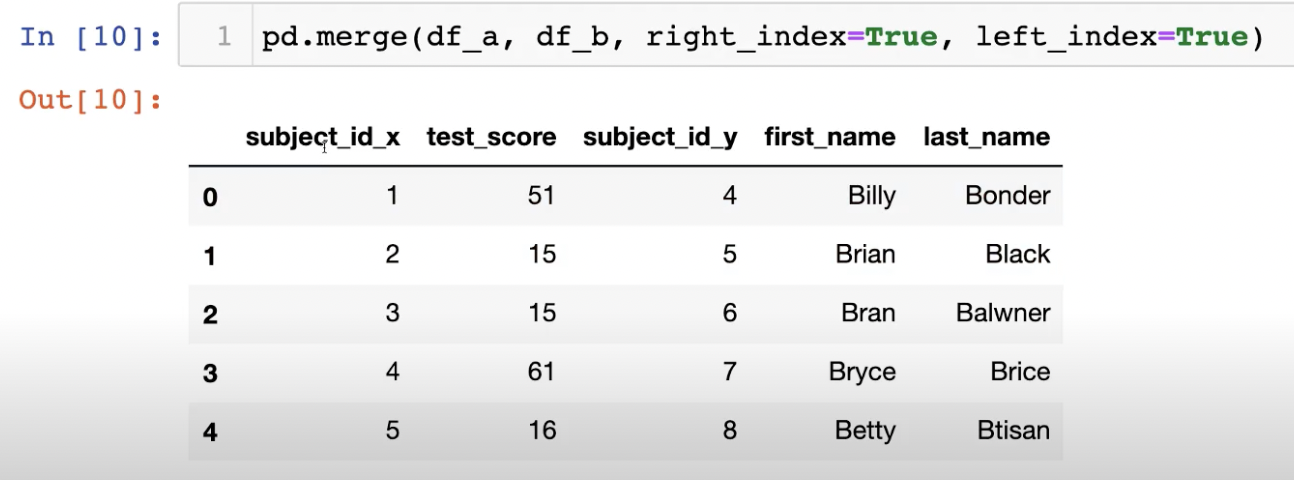
아래처럼 merge를 index 기준으로 해주면 subject_id_x, subject_id_y와 같은
column이 생기기에 이를 drop해줘야 할 일이 생기곤 한다. 주의해서 합치자.
Concat
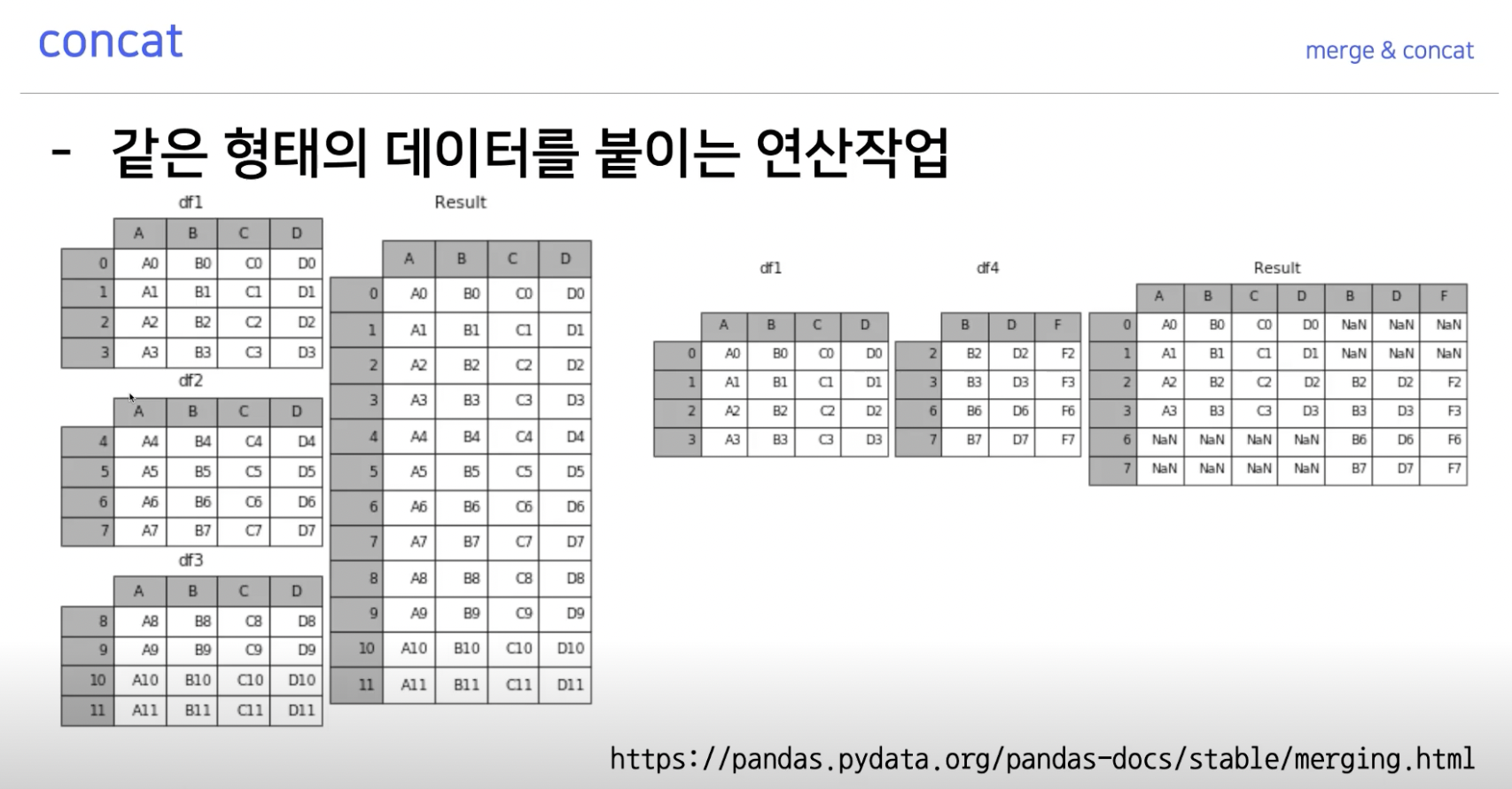
concat은 기본적으로 리스트 형태로 값을 이어붙인다.
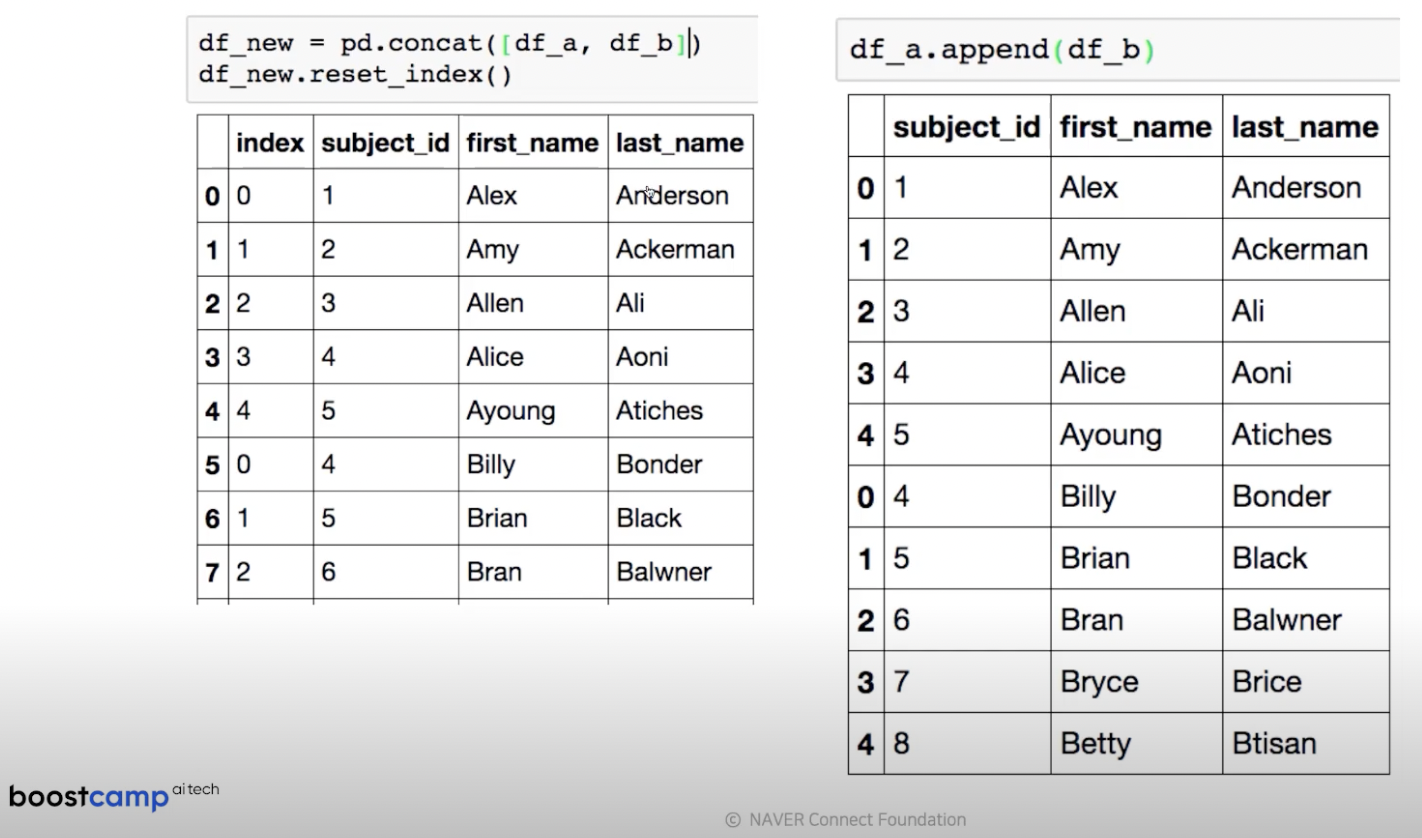

현업에서 데이터를 다루다보면 하루마다, 혹은 월마다 쌓이는 데이터를 다룰 것이다.