3D 연구를 진행하기 위해 읽었던 논문들이 꽤 있는데
노션과 미팅노트 형태로만 정리되어 있어서
논문읽기에 싫증이 나거나 단순한 일을 하고 싶을 때
하나씩 블로그로 옮겨보고자 한다.
그 시작은 NeRF로 - !

2020년 3월, arXiv에 올라와 ECCV 2020 Best Paper로
올라간 (a.k.a) NeRF는 3D Scene Representation을
implicit function으로 encoding하여
고퀄리티의 렌더링 결과를 보여줬다.
Neural Rendering에 관련한 배경지식이 전혀 없었던
나는 애초에 렌더링이라는 개념부터 정립할 필요가 있었다.
렌더링 : 3차원 공간에 존재하는 Object를 2차원,
즉 하나의 장면으로 바꾸어 표현하는 것
NeRF가 푸는 문제의 이름이 Novel View Synthesis인
이유도 여기에 있다. 쉽게 생각하면 우리에게 사과를 양옆
그리고 앞뒤에서 찍은 이미지가 존재한다고 가정하였을 때
정면 기준 좌우 45도 각도에서 찍은 이미지,
나아가 위나 아래에서 찍은 장면까지
합성할 수 있게 하자는 것이다.
어떻게 ? 사과의 3D 정보를 잘 이해할 수 있도록
Neural Network를 학습시키면 되겠다.
Method 소개도 하기 전부터 언급하기 뭐하지만
사과의라는 단어 속에 NeRF의 한계가 잘 드러나 있다.
사과의 3D 정보를 잘 이해한 신경망은
사진 속 물음표에 해당하는 이미지를 합성할 수 없다.
하나의 물체에 하나의 모델이 필요하다는
이 한계점을 해결하기 위해 많은 연구가 진행되었고,
이를 Generalizable NeRF라 일컫는다.
나 역시 이와 관련된 부분을 파고있고,,
차치하고, NeRF로 돌아가 그 Input과 Output을 살펴보자.
아까 봤던 이미지를 함께 보면서 이해하면 좋겠다.
포크레인을 둘러싼 가상의 직육면체 공간이 있고,
우리는 x, y, z 3차원 좌표를 활용하여
그 공간 속 임의의 위치를 표현할 수 있다.
또 하나 생각해 볼 것은 동일한 3차원 위치라도
다른 각도에서 바라보면 다른 컬러로 관찰될 수 있다.
포크레인 운전자의 머리 좌표를 입력으로 넣는데
포크레인 정면인 view direction을 입력으로 함께 넣으면
물체를 드는 버켓 때문에 운전자가 보이지 않는다.
반면, 운전자 머리 좌표를 넣고 우측 view direction을
함께 넣으면 운전자의 머리가 관찰될 것이다.
이미지 한 장이 주어졌을 때,
학습 파이프라인을 그려보면 학습이미지가 주어졌다는 것은
GT 픽셀값과 View Direction이 주어졌다는 것.
64 x 64 이미지로 가정하자. 4,096개의 픽셀이 존재하겠다.
(0,0)에서 그 이미지에 해당하는 View Direction으로
Ray를 쏘자. Ray 위 모든 점에서 컬러를 뽑는건 불가능하다.
Sampling을 진행할 것인데
같은 간격으로 샘플링하는 Uniform Sampling을 가정하자.
샘플링 된 점의 3D Position, 해당 ray의 view direction이
입력으로 들어가고 잘 학습된 MLP는 그 포인트의
Color와 Density를 출력으로 내뱉는다.
Ray를 따라 모든 점들의 Color 값이 나올 것이고,
그 값들을 Weighted Sum 하여 최종 컬러값을 산정한다.
이 값을 누구와 비교할까?
바로 아까 이미지의 (0,0) 픽셀값과 비교하는 Loss를 통해
Multi Layer Perceptron Network가 학습된다.
질문이 나오겠다. Color는 알겠는데 Density는 뭔데 ?

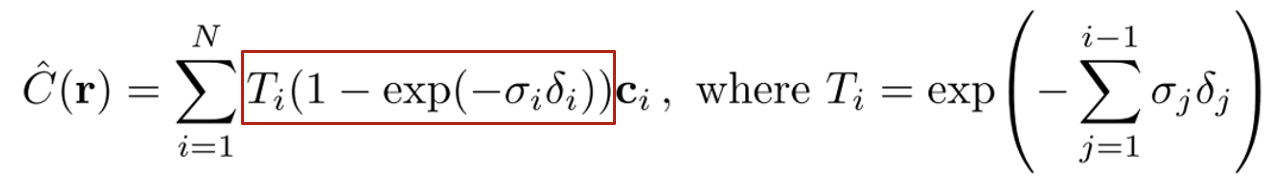
Density는 Weighted Sum에 쓰이는 Value다.
아까 예로 들었던 포크레인을 떠올려보면 정면에서 볼 때
운전자의 머리가 보이지 않는 이유가 무엇인가?
포크레인의 버켓 때문이었다. 이러한 특징을 네트워크가
알아차릴 수 있게 돕는 값이 바로 Density다.
정면 View Direction에서 운전자의 머리가 존재하는
3차원 좌표의 컬러값을 뽑았다고 가정하자.
Sigma에 더해질 때 포크레인 버켓 색의 Density는 크게,
운전자의 머리 색의 Density는 작게 더해져야 해당 정면
이미지에서 운전자의 머리가 아닌 포크레인의 버켓이
보이지 않을까. 수식으로 살펴보면 더욱 이해가 쉽다.
Weighted Sum을 계산할 때 두 조건이 위 식 속에
빨간 박스 안에 나타나있다. T를 먼저 보면 exponential
y축 대칭 꼴을 생각하면 되니까 들어가는 값이 커질수록
함수값은 줄어든다. 시그마의 상한을 보니 현재 포인트의
직전까지 더한다. 바로 두 번째 조건에 해당하는 수식이다.
이전 포인트까지 이미 Density 합이 너무 크면 현재 포인트
색은 Weighted Sum에서 큰 역할을 하면 안된다는 것이다.
그렇다면 빨간상자 오른쪽 텀은 첫 번째 조건에 해당하겠다.
현재 포인트의 Density가 크게 나오면 색이 더 강조되어야
한다는 텀이다. 이 두 텀을 통해 3D 공간의 특징을 학습한다.

거의 다왔다. 다만, Loss 식이 저렇게 생기지 않았다.
바로 샘플링이 Uniform 샘플링이 아니기 때문이다.
단순하게 같은 간격으로 샘플링해서 Weighted Sum을
먹이면 주요 포인트가 샘플링 되지 않을 리스크가 있다.
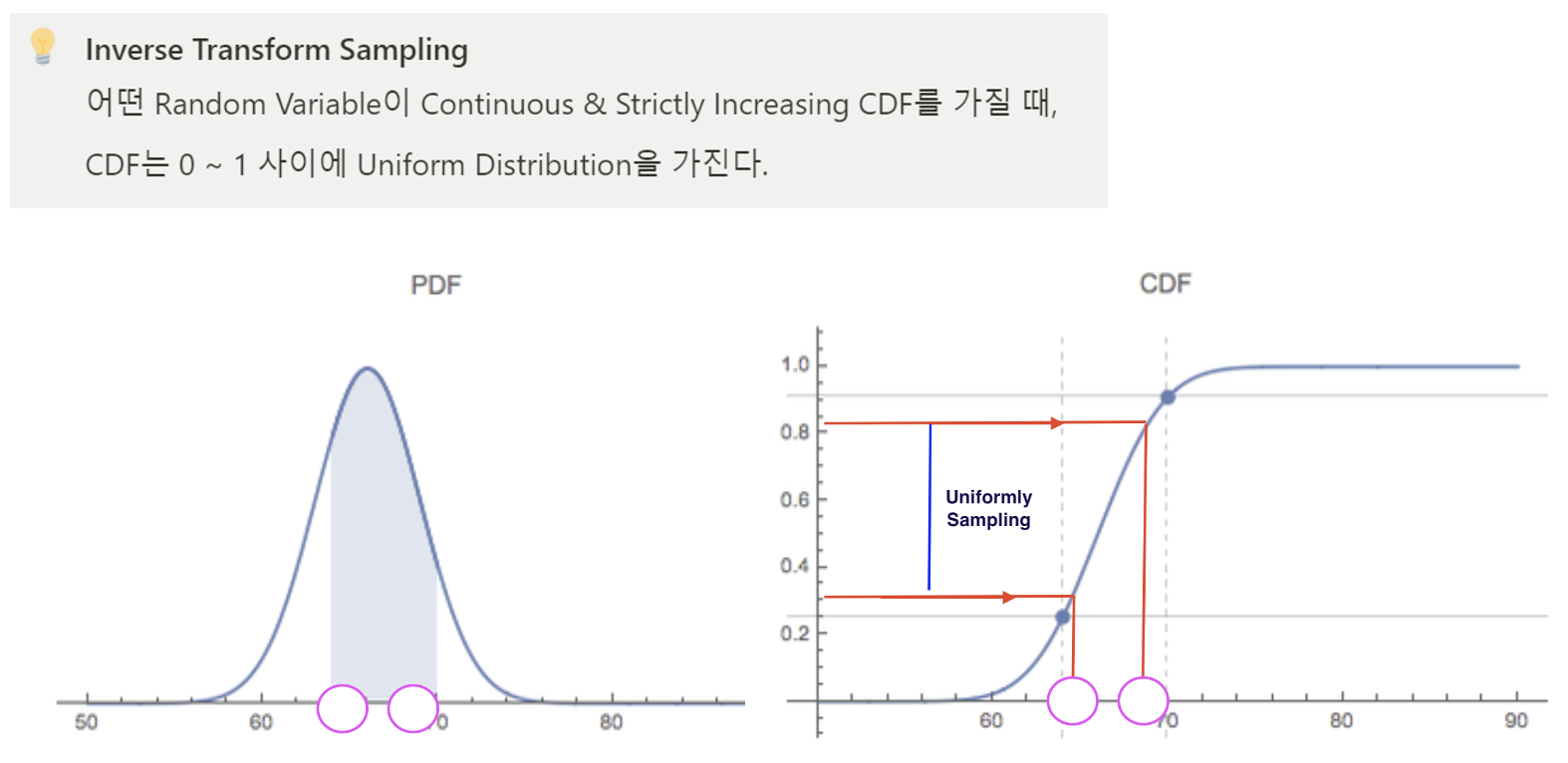
Hierarchical Volume Sampling 개념은 아래와 같다.

처음엔 Uniform Sampling을 통해 샘플링을 진행하고,
MLP1에 넣어 Density 값을 쭉 뽑으면 아래 PDF 형태가
될 것이고, 여기서 Inverse Transform Sampling 기법을
적용하여 Density가 높은 곳을 위주로 점들을 샘플링하여
MLP2에 넣는다. 각 MLP가 Coarse Network 그리고
Fine Network가 되는 것이며, 구조는 동일하다.
논문 리뷰와 개념에 대한 설명은 얼추 마무리 된 것 같다.
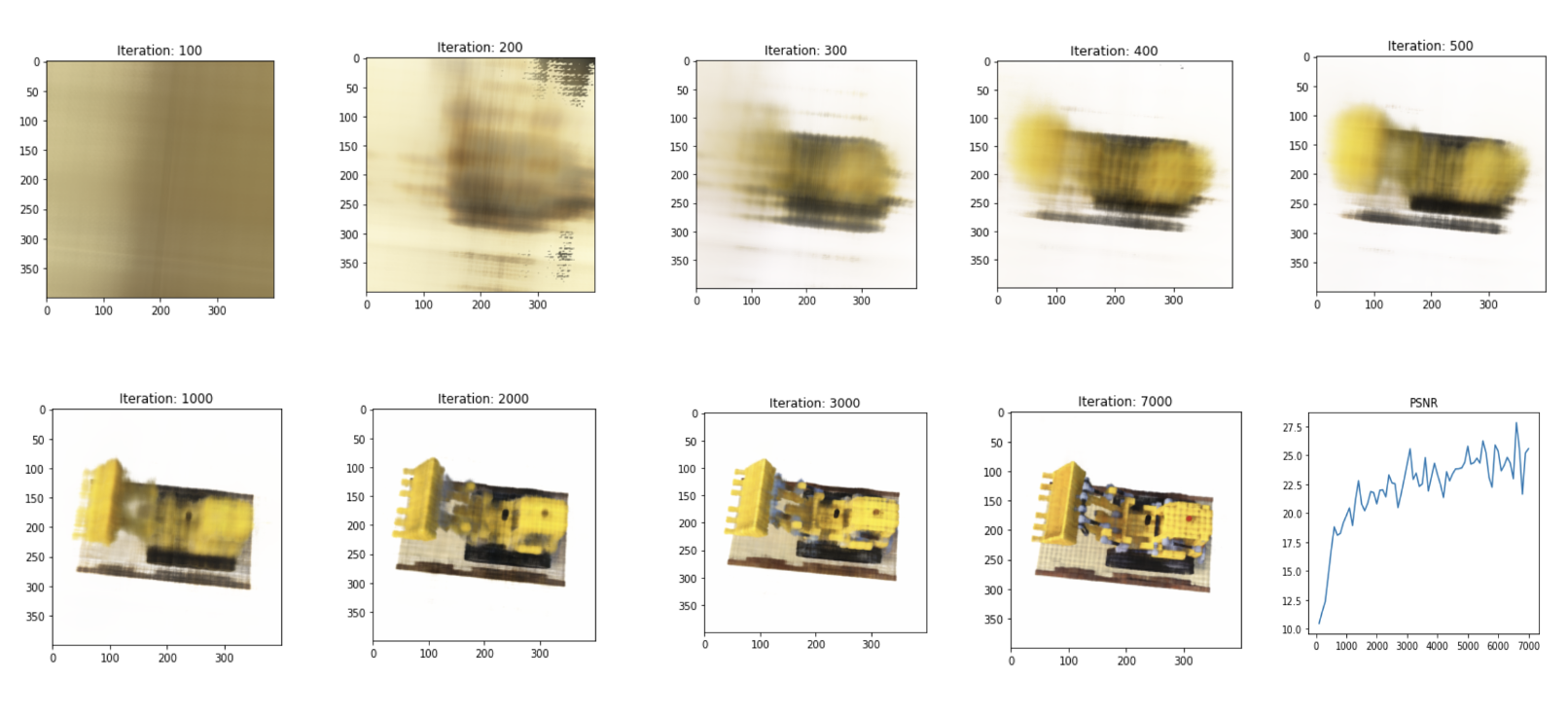
Blender Dataset에 대해 돌려본 결과는 아래와 같다.
Per-Scene Optimization에 의존하기 때문에
학습이 꽤 걸리지만 퀄리티는 좋은 것을 확인할 수 있다.
2020년 ECCV에 NeRF가 등장한 뒤로 관련 연구가
정말 말그대로 쏟아져나왔다. 이 분야를 연구하겠다고
마음을 먹고, 최신논문들을 열심히 팔로우업 하자 했지만
이번 CVPR, SIGGRAPH까지 관련 연구가 계속해서
나오고있다. 선배들만 봐도 본인이 하고있는 연구와 유사한
연구가 이번 학회에서 나오지 않을까 조마조마해하는걸
어렵지 않게 볼 수 있었는데 곧 나의 미래 같기도 하다.
초조하기도 하지만 화이팅해보자..!
'AI > Novel View Synthesis' 카테고리의 다른 글
| D-NeRF : Neural Radiance Fields for Dynamic Scenes 논문 리뷰 및 설명 (2) | 2023.09.26 |
|---|