모든 게시물은 macOS Monterey 12.0.1 버전 기준으로 작성하였습니다.
'이것이 취업을 위한 코딩 테스트다 with 파이썬' 토대로 작성하였습니다.
< 복습 >
- for문 쓸 때 무조건 for i in range() 가지 말고 리스트 그대로 iteration 할까도 고려하자.
- if l[i] == 0 or 1 으로 조건문 걸면 False or True로 인식해서 다 참으로 간다.(그런듯?)
- ㅣ = [] 형태로 리스트 초기화 후 for문에 l[i] 인덱싱하면 out of index 나온다.
- 리스트 sorting 할 때 l = l.sort() 하면 값 없어진다. 그냥 l.sort() 써라.
- 리스트 크기를 size(l)로 구할 수 없다. len(l)로 구해라.
- 그래프 모델링 할 때는 노드 인덱싱과 맞추기 위해 그래프의 첫 리스트를 []로 초기화한다.
- DFS는 재귀 함수 형태로 해결하고, BFS는 while queue로 반복문을 건다.
- BFS는 방문 처리하기 전에 popleft로 원소를 빼주고, 방문처리하면 append 잊지 말자.
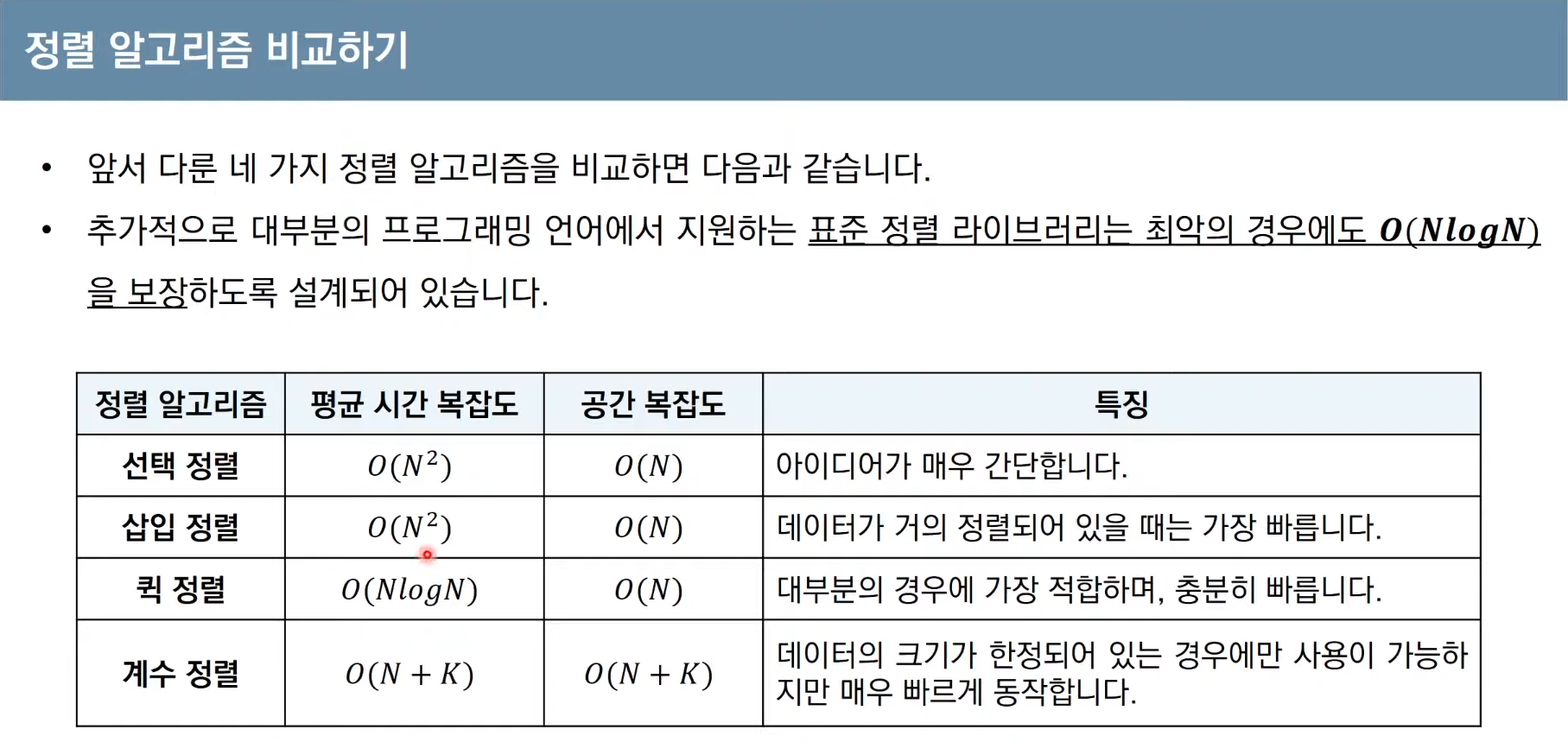
정렬 알고리즘
정렬이란 데이터를 특정한 기준에 따라서 순서대로 나열하는 것을 의미한다.
정렬 알고리즘으로 데이터를 정렬하면 다음 장에서 배울 이진 탐색이 가능해진다.
그 종류가 다양한데 선택 정렬, 삽입 정렬, 퀵 정렬, 계수 정렬을 다룰 것이다.
일반적으로 문제 상황에 따라 적절한 정렬 알고리즘이 공식처럼 존재하며,
이는 코딩 테스트뿐만 아니라 면접에서도 자주 출제된다.
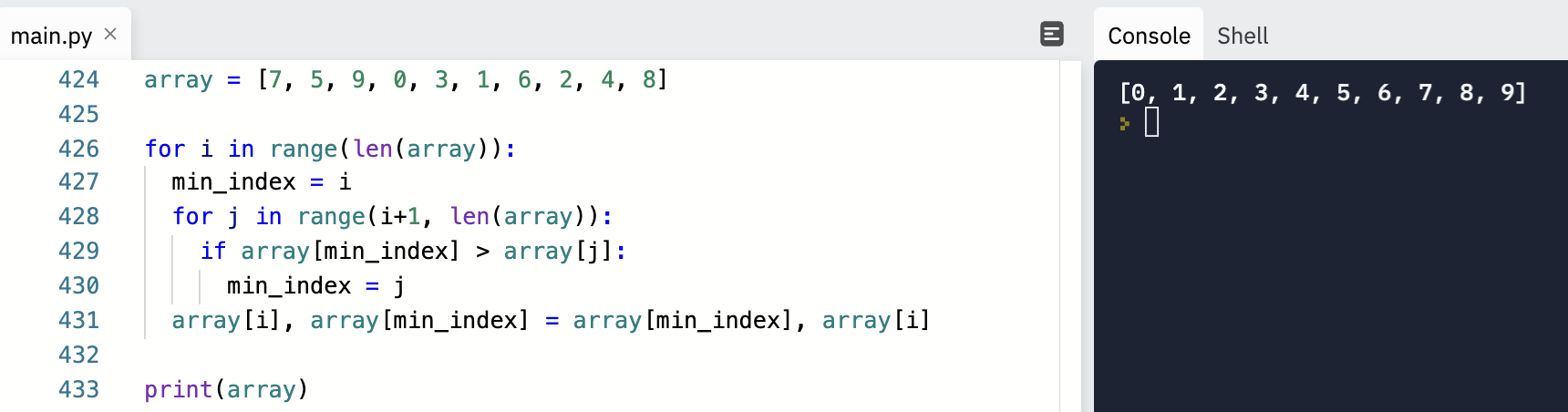
1. 선택 정렬
데이터가 무작위로 여러 개 있을 때,
처리되지 않은 데이터 중에서 가장 작은 데이터를 선택하여 맨 앞 데이터와 바꾸고,
그다음 작은 데이터를 선택하여 앞에서 두 번째 데이터와 바꾼다.
가장 원시적인 방법으로 매번 '가장 작은 것을 선택'한다는 의미에서 선택 정렬이다.

데이터의 개수가 N이라고 할 때,
가장 작은 데이터를 앞으로 보내는 과정을 N-1번 반복하면 정렬이 완료된다.
위 코드는 스와프(Swap)에 대해 모른다면 이해하기 어려울 수 있다.
스와프란 특정한 리스트가 주어졌을 때 두 변수의 위치를 변경하는 작업을 뜻한다.
선택 정렬은 기본 정렬 라이브러리를 포함해 뒤에 다룰 알고리즘에 비해 비효율적이나
특정한 리스트에서 가장 작은 데이터를 찾는 일이 코딩 테스트에서 잦으므로
선택 정렬 소스코드 형태에 익숙해질 필요가 있다.

2. 삽입 정렬
'데이터를 하나씩 확인하며, 각 데이터를 적절한 위치에 삽입하면 어떨까?'
위 문장이 삽입 정렬의 아이디어다.
특히 삽입 정렬은 필요할 때만 위치를 바꾸므로 더 효율적인 알고리즘이다.
삽입 정렬은 특정한 데이터가 적절한 위치에 들어가기 이전에,
그 앞까지 데이터는 이미 정렬되어 있다고 가정한다.
가령 7 5 9 0 3 1 6 2 4 8을 정렬한다고 하자.
삽입 정렬은 두 번째 데이터부터 시작하는데
첫 번째 데이터는 그 자체로 이미 정렬되어 있다고 판단하기 때문이다.


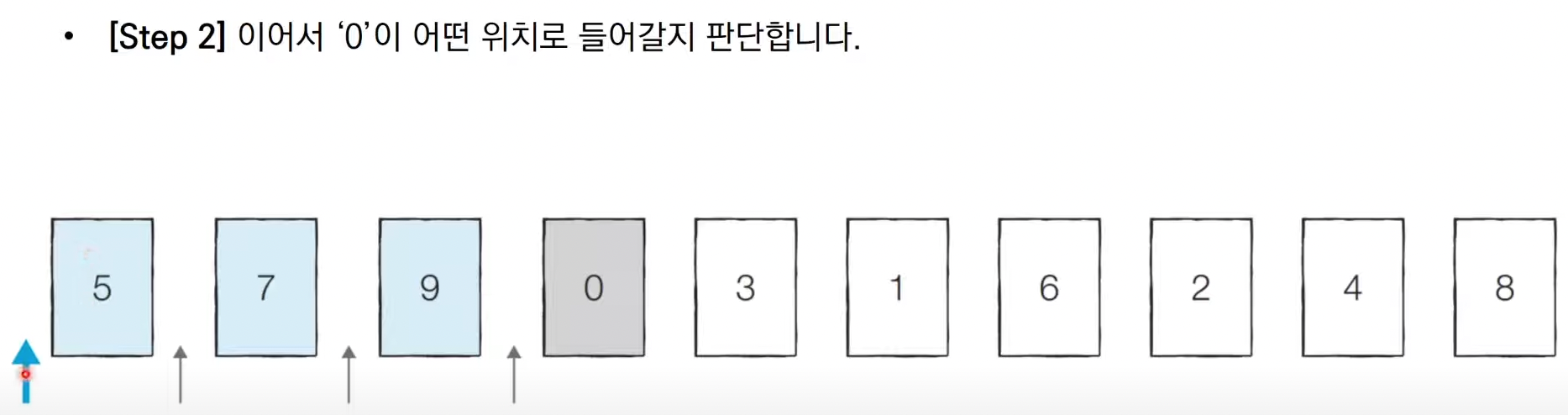
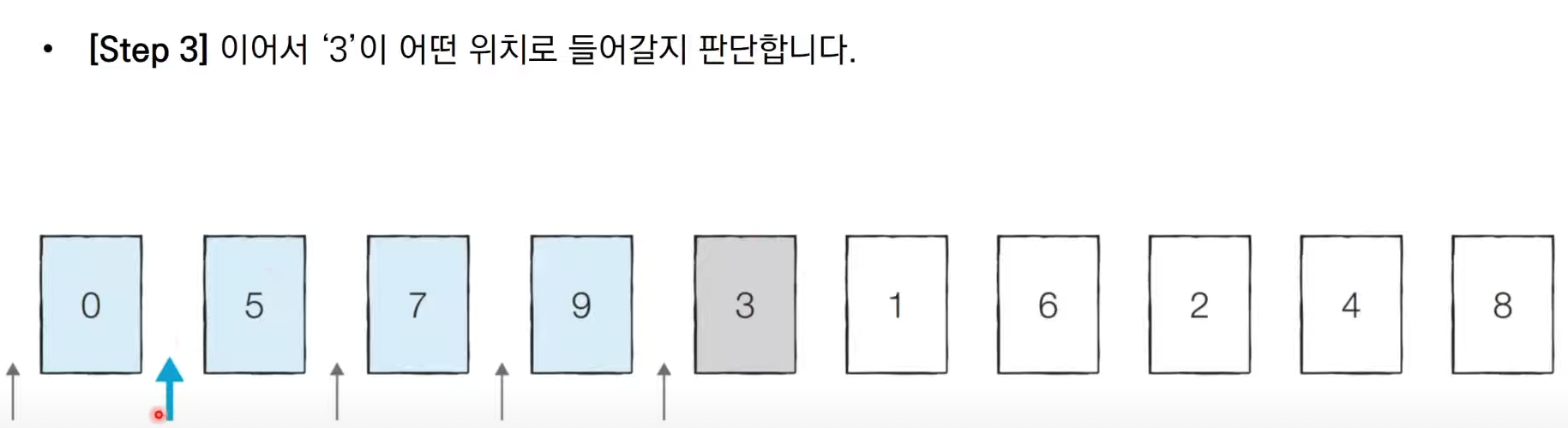
위와 같이 적절한 위치에 삽입하는 과정을 N-1번 반복하게 되면 정렬이 끝난다.
저자가 재미있다고.. 말하는 특징은 정렬된 즉, 파란색으로 칠해진 데이터는 항상
오름차순을 유지하고 있다는 것이다. 이걸 어떻게 써먹을 수 있느냐.
검은색 3의 위치를 정할 때, 한 칸 씩 왼쪽으로 가다가 자기보다 작은 놈이 나오면
그 자리가 바로 3의 자리가 된다는 것을 확신할 수 있다는 것이다. "재밌다."



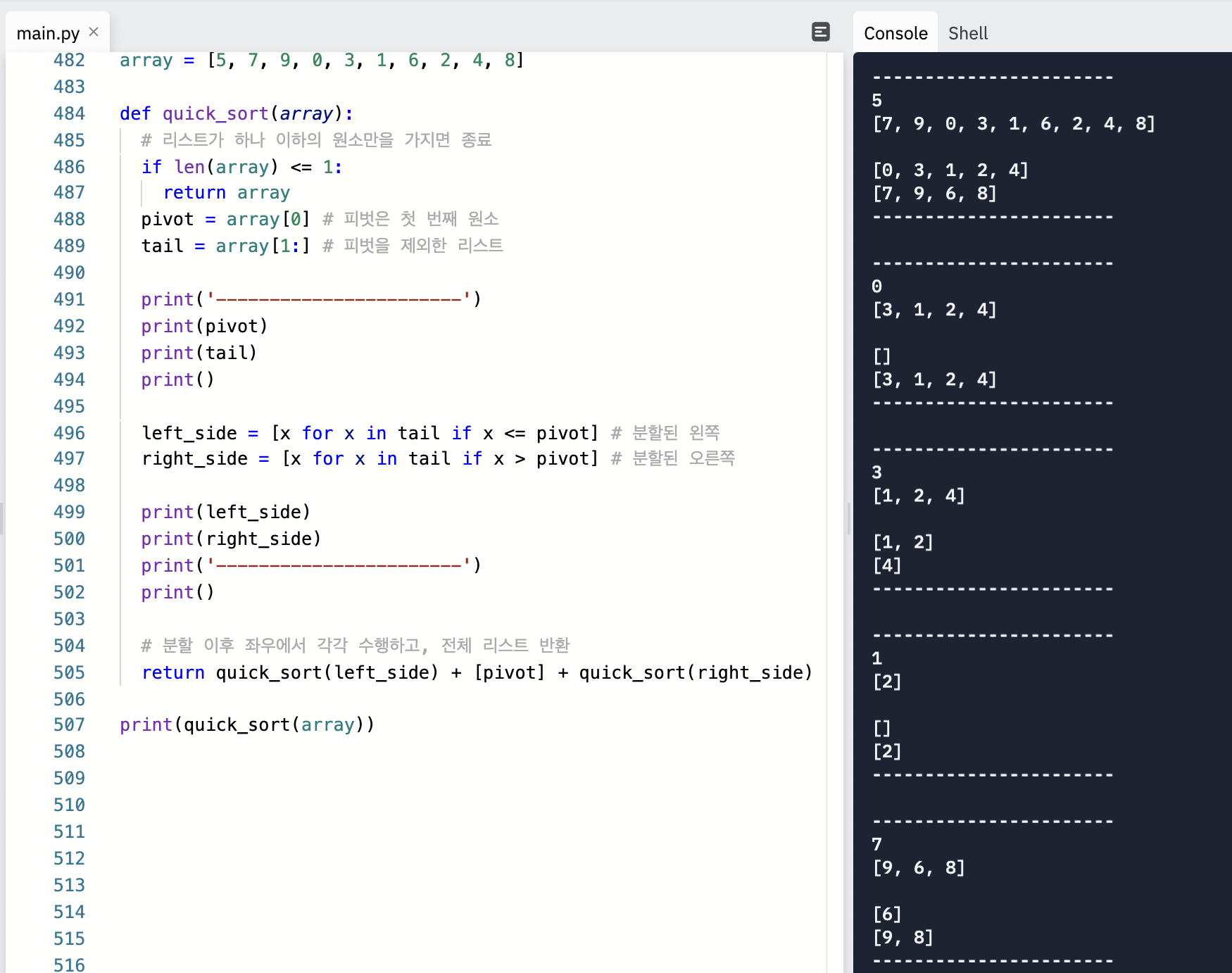
3. 퀵 정렬
퀵 정렬은 지금까지 배운 정렬 알고리즘 중에 가장 많이 사용되는 알고리즘이다.
이와 비교할 만큼 빠른 알고리즘으로 병합 정렬 알고리즘이 있는데 추후 자습하자.
퀵 정렬의 아이디어는 다음과 같다.
'기준 데이터를 설정하고 그 기준보다 큰 데이터와 작은 데이터 위치를 바꾸자.'
퀵 정렬은 기준을 설정한 다음 큰 수와 작은 수를 교환한 후 리스트를 반으로 나눈다.
퀵 정렬에서는 큰 숫자와 작은 숫자를 교환할 때 기준 역할을 하는 피벗이 쓰인다.
피벗을 설정하고 리스트를 분할하는 방법에 따라 퀵 정렬도 분류되지만
가장 대표적인 분할 방식인 호어 분할 방식을 기준으로 퀵 정렬에 대해 알아보자.
이는 첫 번째 데이터를 기준 데이터인 Pivot으로 설정하고 진행한다.


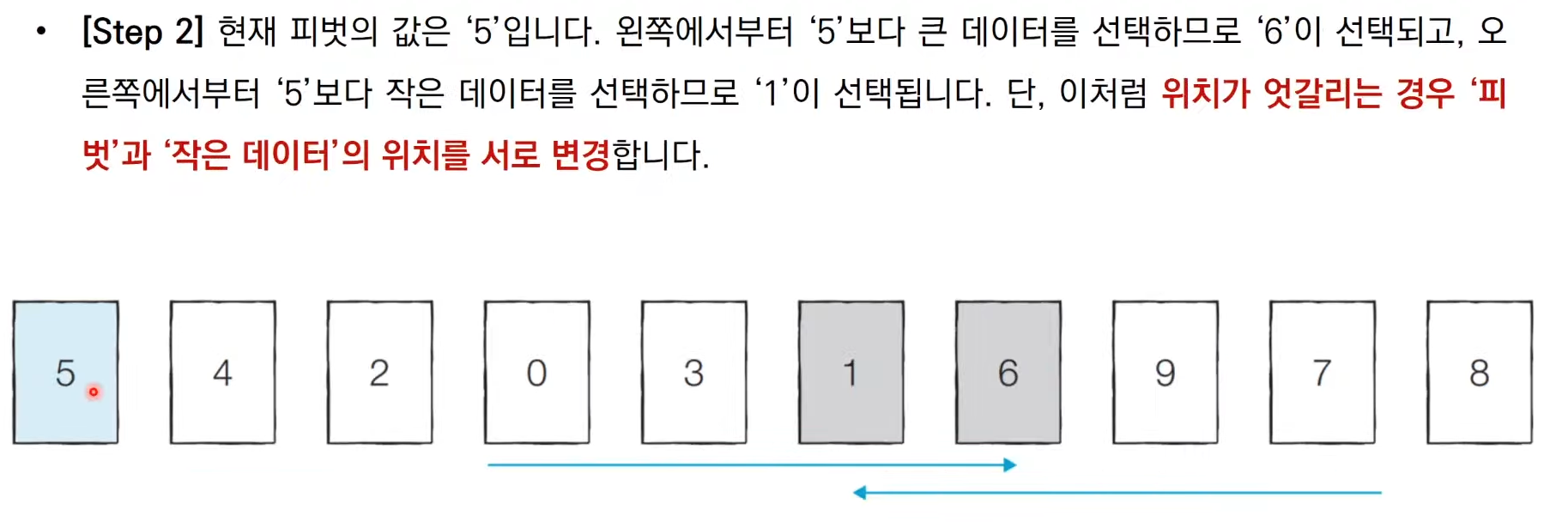
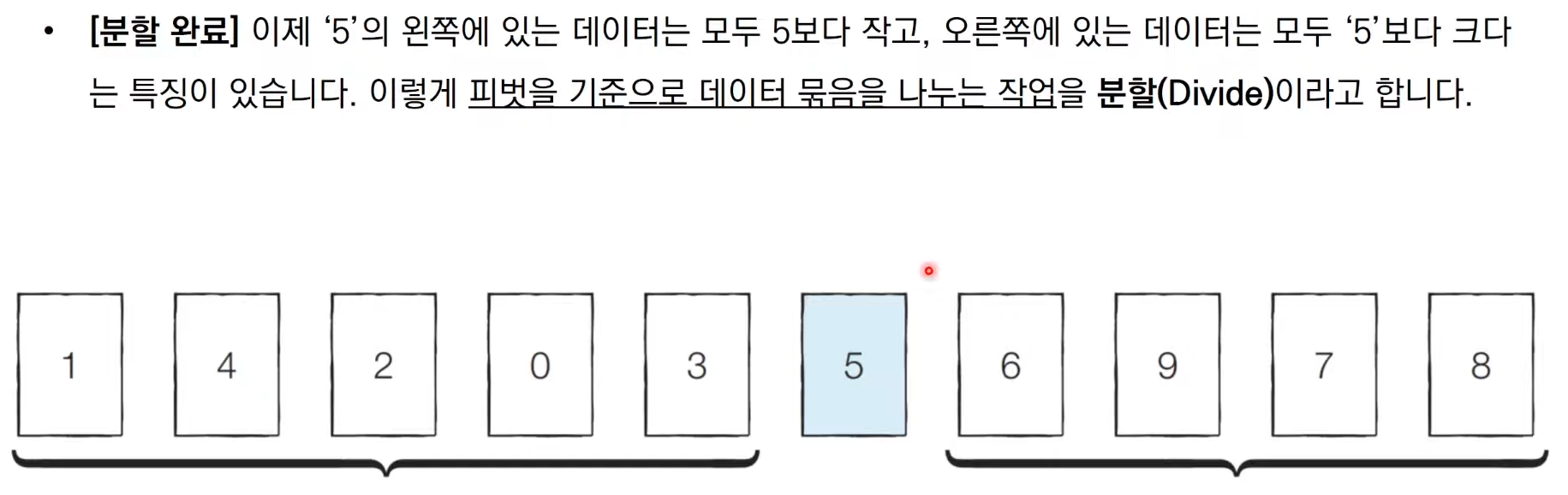
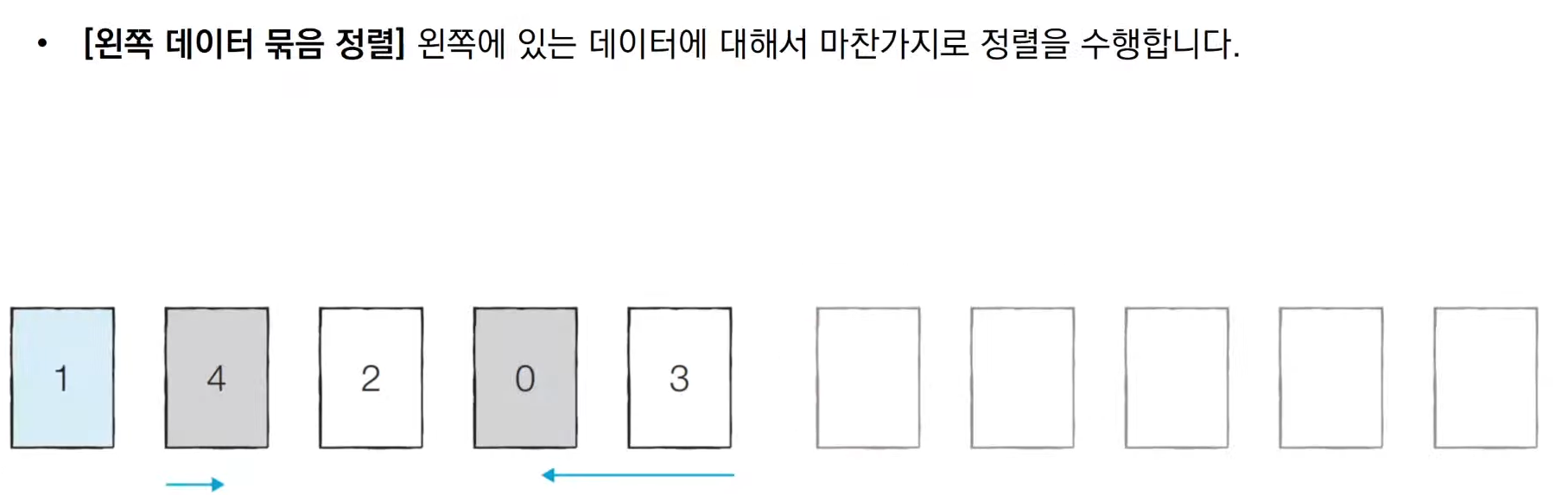
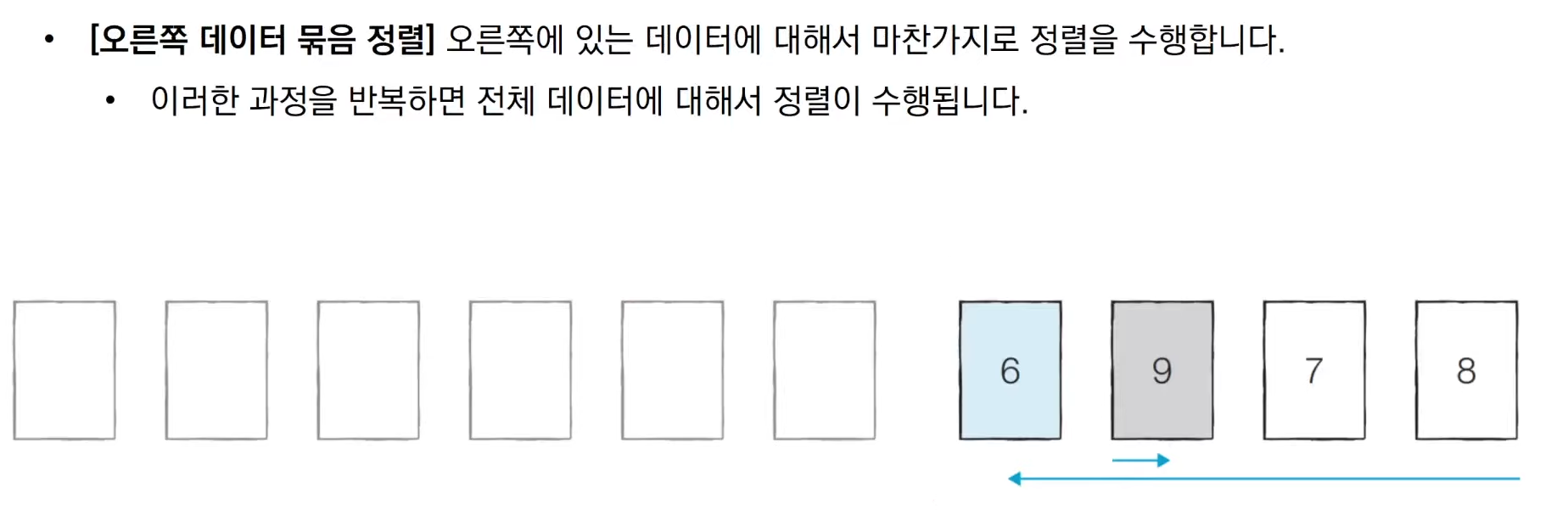
위 과정은 종이를 잘라 숫자를 적어 직접 해보는 것을 권한단다.
그래서 해봤다. 이건 리터럴리 재밌었다. 피벗을 기준으로 왼쪽 리스트와 오른쪽
리스트에서 각각 다시 정렬을 수행하니 재귀 함수를 이용하면 좋겠다.
퀵 정렬이 끝나는 조건은 현재 리스트의 데이터 개수가 1개인 경우다.


퀵 정렬의 시간 복잡도에 대하여 한 가지 기억해둘 점이 있다.
평균 시간 복잡도는 O(NlogN)이지만 최악의 경우 O(N^2)이고,
앞서 다룬 삽입 정렬과 다르게 이미 데이터가 정렬되어 있을 때가 오히려 최악이다.
분할이 절반에 가깝게 이루어지지 않고 편향된 분할이 일어났기 때문이다.
Pivot 값에서 계속 오른쪽만 남으니 분할 회수 N번에,
분할하기 위한 선형탐색이 있으니 총 시간 복잡도가 O(N^2)이 되는 것이다.

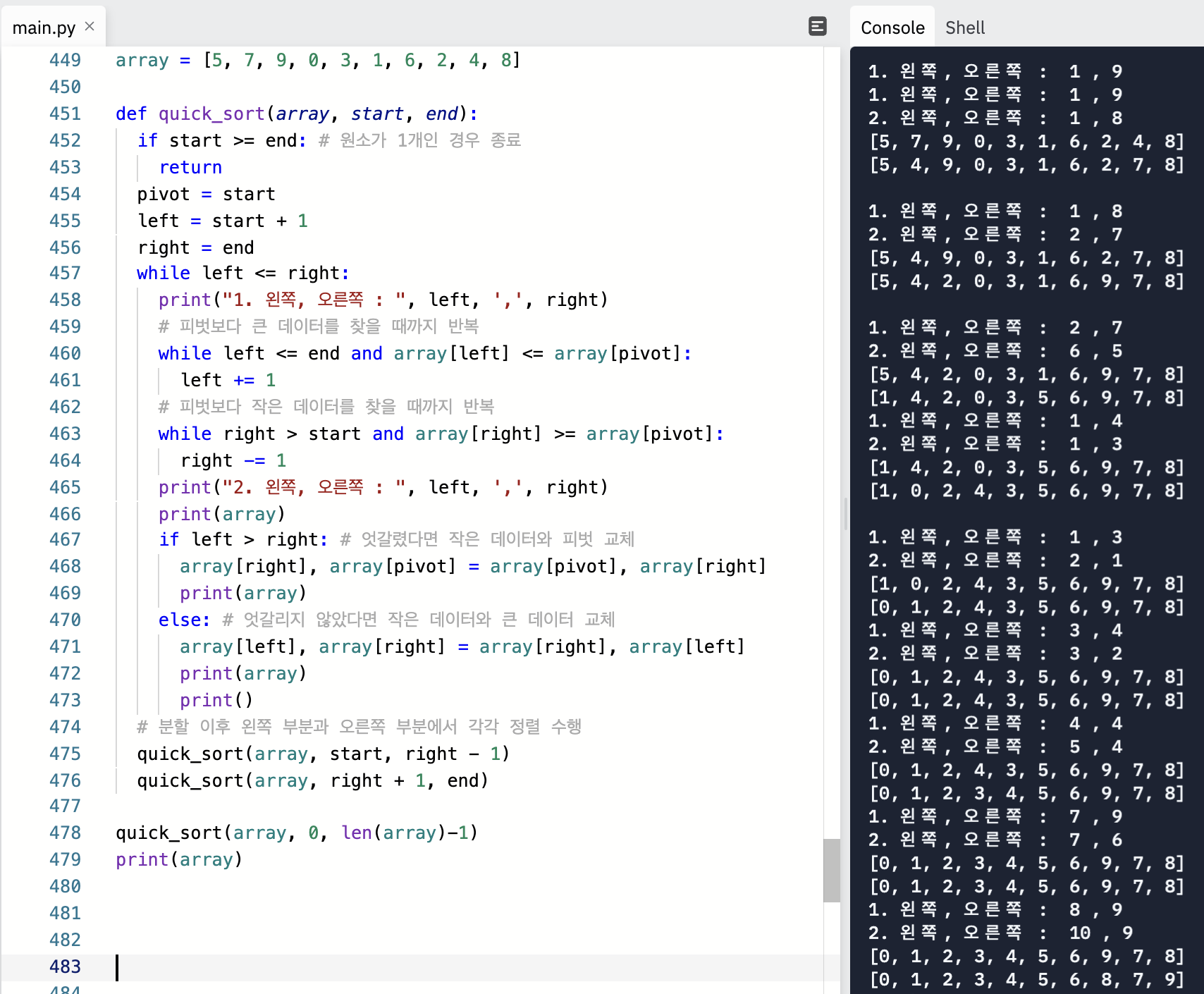
파이썬의 장점을 살려 짧게 작성한 퀵 정렬 소스코드를 공부해보자.
위 방법보다 피벗과 데이터를 비교하는 연산이 증가하지만 직관적이고 이해가 쉽다.

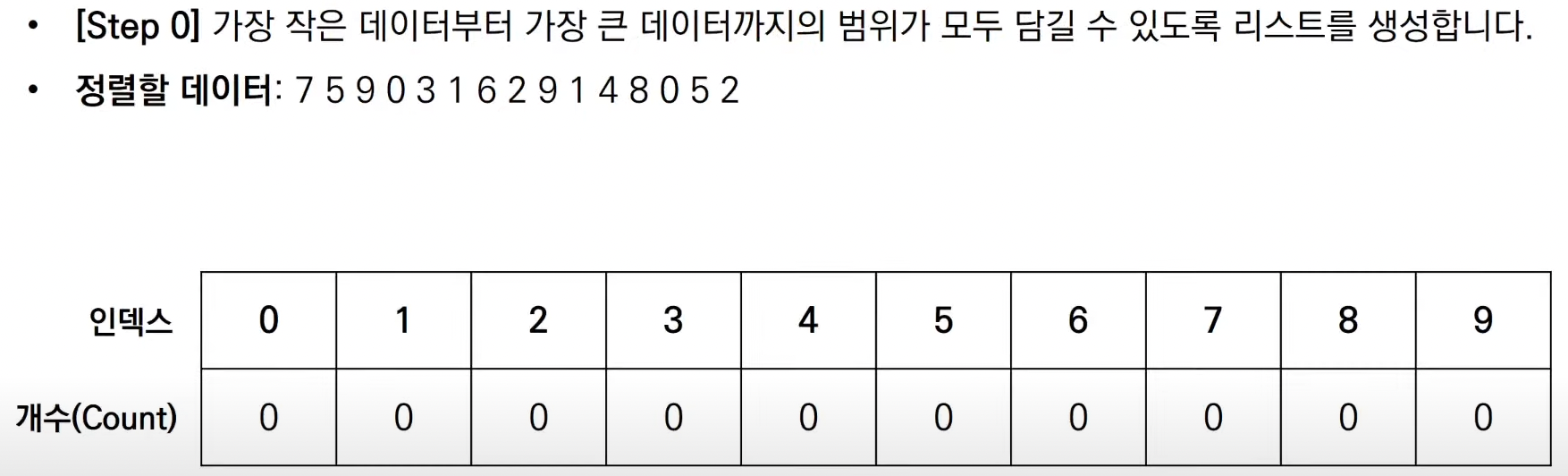
4. 계수 정렬 ( Counting Sort )
계수 정렬은 특정한 조건이 부합할 때만 사용할 수 있으나 매우 빠른 알고리즘이다.
모든 데이터가 양의 정수인 상황을 가정해보자.
데이터 개수가 N, 최댓값이 K면 계수 정렬은 최악의 경우에도 O(N+K)를 보장한다.
다만, 계수 정렬은 데이터 크기 범위가 제한되어 정수 형태로 표현이 가능해야 한다.
예를 들어 최소와 최대 차이가 1,000,000이라면 계수 정렬을 진행하기 위하여
1,000,001개의 데이터가 들어갈 수 있는 리스트를 초기화해야 한다.
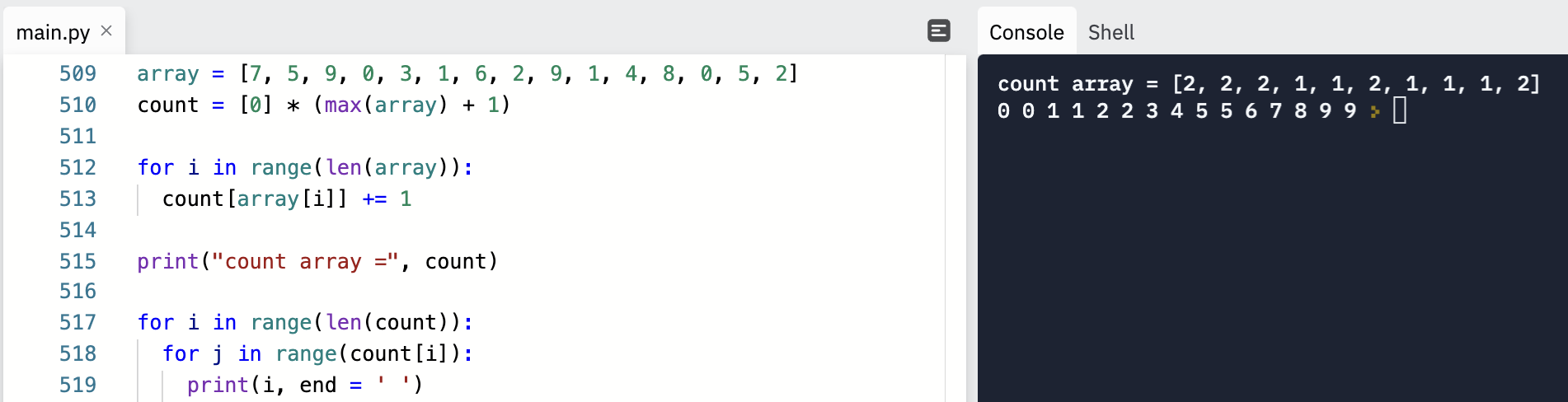
계수 정렬 알고리즘 방식에 대해 알아보자.
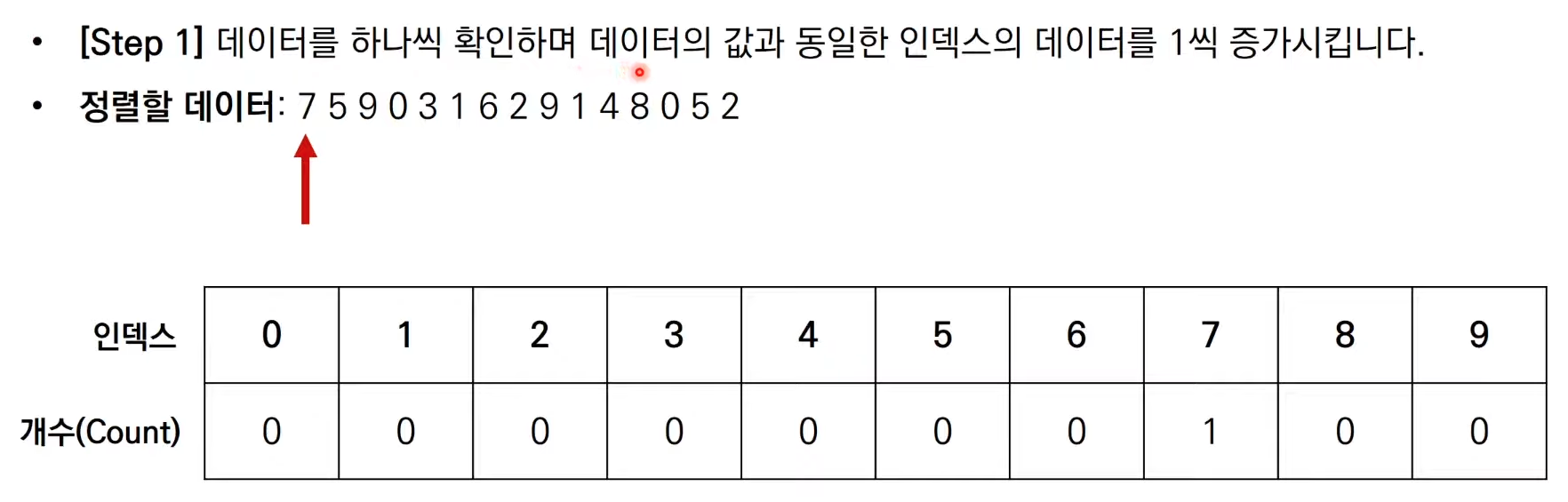
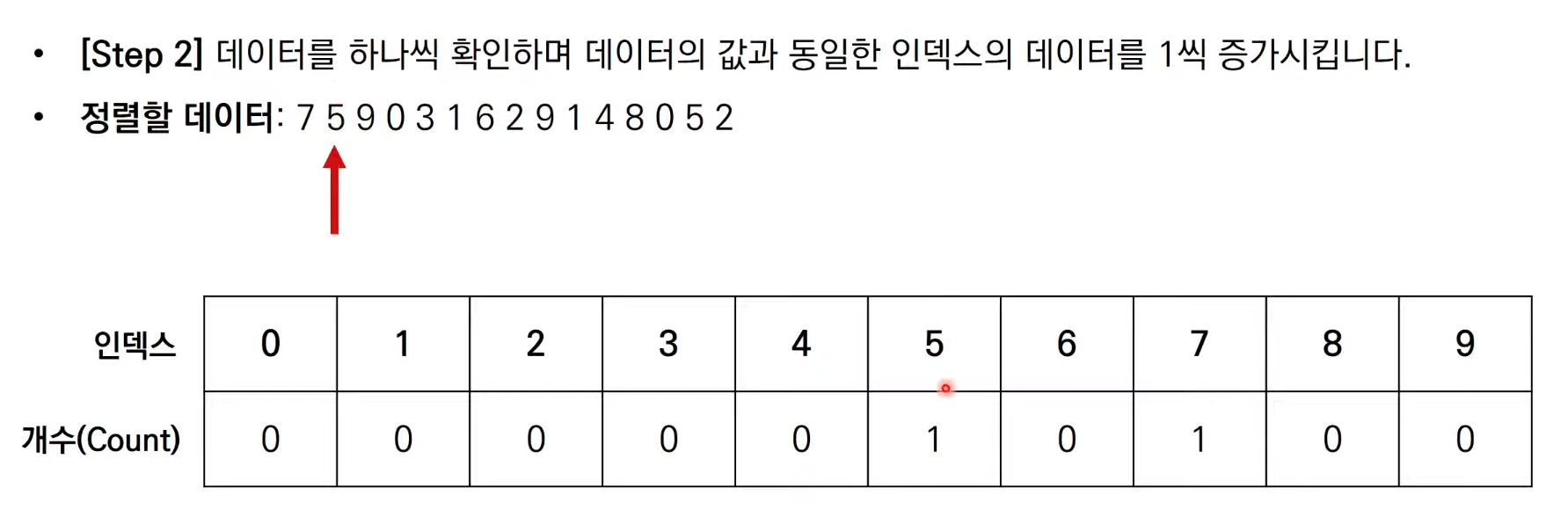
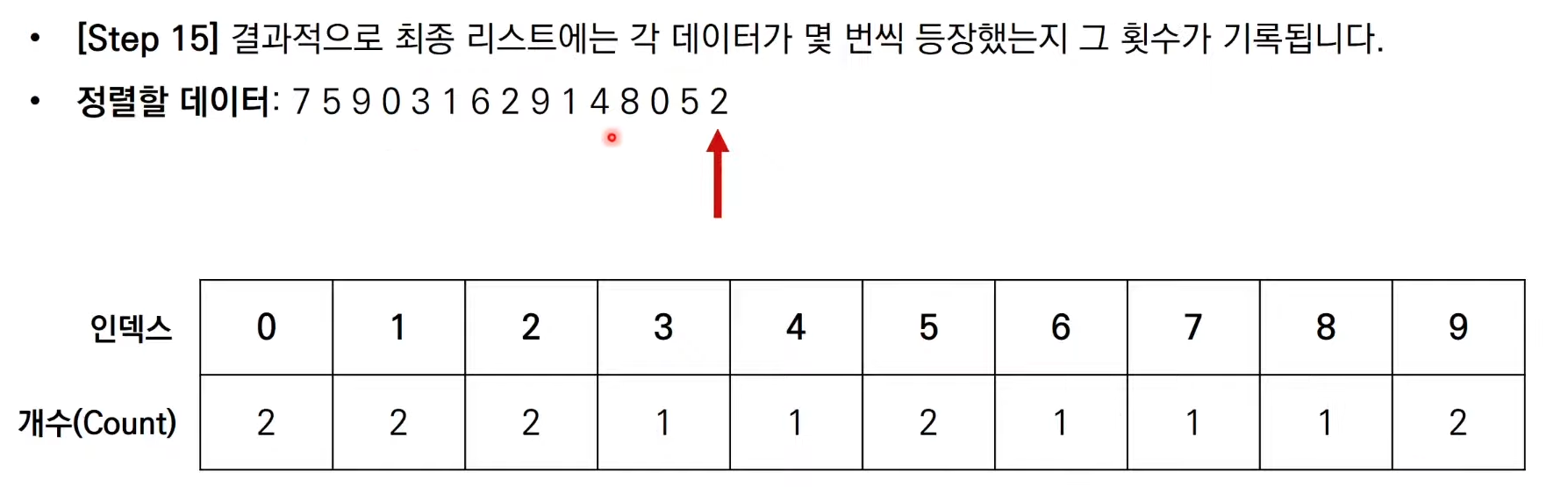
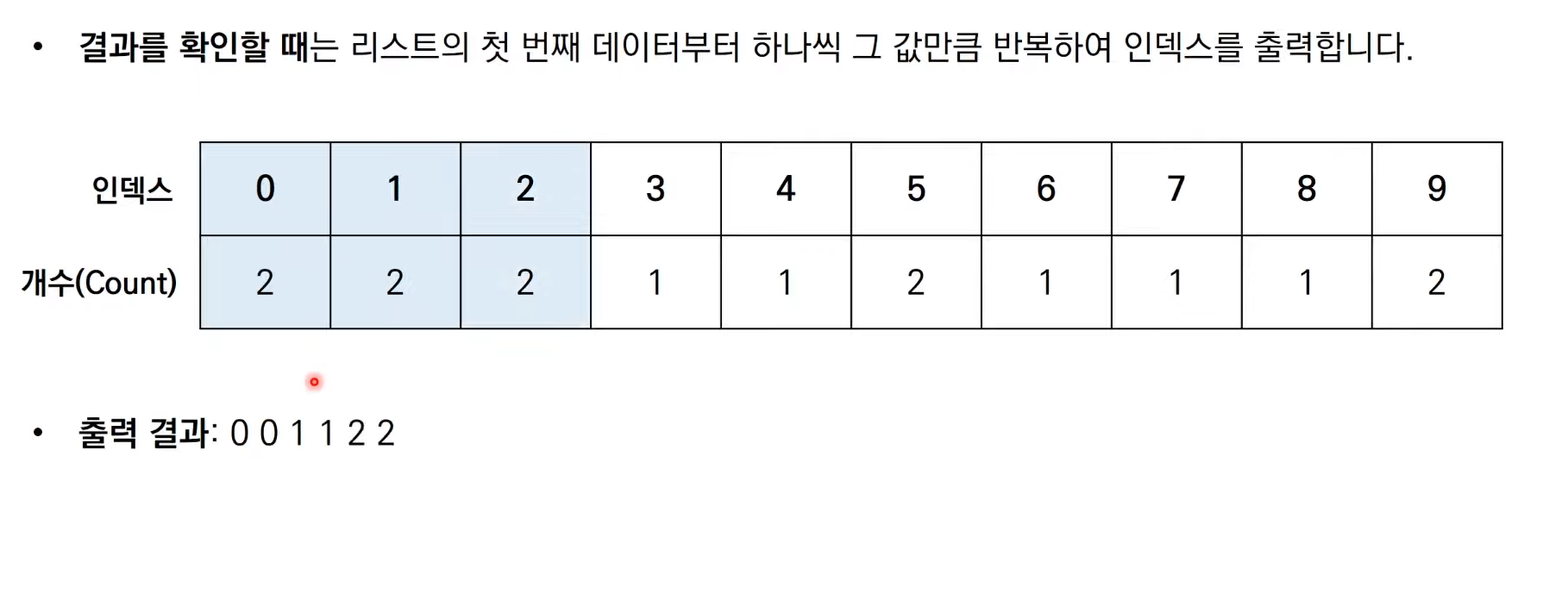
계수 정렬은 앞서 다루었던 3가지 정렬 알고리즘 처럼 데이터 값을 비교하여
그 위치를 변경하는 비교 기반의 정렬 알고리즘이 아니다.
비교적 그 구현이 간단하고 이해하기 쉬운 계수 정렬이지만 때에 따라서
심각한 비효율성을 초래할 수 있는데 데이터가 0과 999,999만 있는 경우가 그렇다.
이럴 때도 리스트의 크기가 100만 개가 되도록 선언하여 이들을 정렬해야 한다.
따라서 항상 사용할 수 있는 정렬 알고리즘은 아니며. 동일한 값을 가지는 데이터가
여러 개 등장할 때 사용하기에 적합하다. 예를 들어 성적의 경우, 같은 성적을 가진
학생 수가 다수일 수 있기 때문에 계수 정렬을 사용할 수 있다.


< 정렬 알고리즘 정리 >
정렬 알고리즘 코딩 테스트 연습문제



풀었다. 이정도 난이도로 가득한 코딩 테스트면 모두가 만점이려나.
해설을 보니 이 문제의 핵심은 시간 복잡도에 있었다.
두 배열의 원소가 최대 100,000개까지 입력될 수 있으므로 O(N^2)을 쓸 수 없다.
최악의 경우에도 O(NlogN)을 보장하는 정렬 알고리즘을 활용해야 한다.
아래 답안과 내 풀이가 다르니 확인하자.


< 연습 문제 >
N명의 학생 정보가 있다.
첫 번째 줄에 학생의 수 N이 입력된다.
두 번째 줄부터는 학생의 이름과 점수가 입력된다.
모든 학생의 이름을 성적이 낮은 순서대로 출력하라.
- 입력 예시 -
2
홍길동 95
이순신 77
- 출력 예시 -
이순신 홍길동
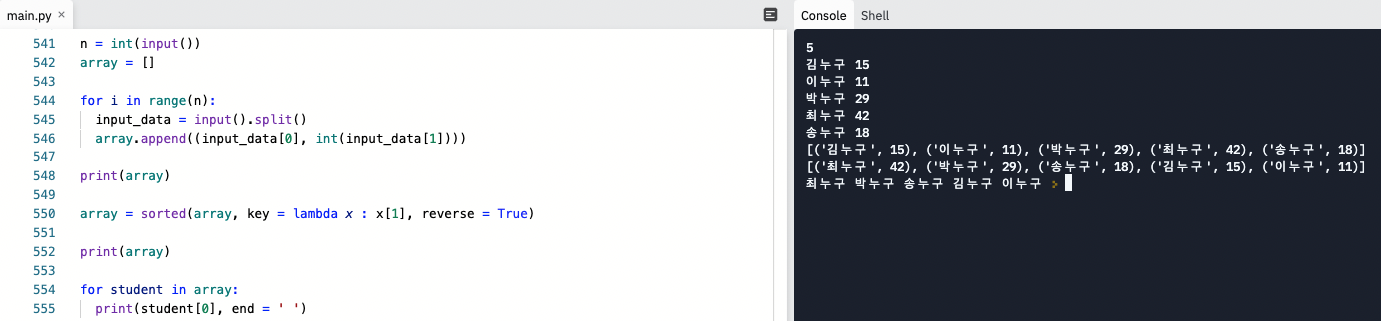
sorted에 key를 작성할 때 lambda function 쓰는 것에 익숙해지자.
또, 리스트 속에 튜플 형태로 나란히 넣고 그중 하나의 원소를 정렬 기준으로
사용할 수 있음을 기억하자. 이때, key를 사용한다는 점 !
'Python > 이코테 with 파이썬 정리' 카테고리의 다른 글
| [211221] 코딩 테스트를 위한 투 포인터 알고리즘 (0) | 2021.12.21 |
|---|---|
| [211217] 코딩 테스트를 위한 이진 탐색 알고리즘 (0) | 2021.12.17 |
| [211216] 코딩 테스트를 위한 깊이 우선 탐색, 너비 우선 탐색 ( DFS & BFS ) (0) | 2021.12.16 |
| [211210] 코딩 테스트를 위한 그리디 알고리즘 ( Greedy Algorithms ) (0) | 2021.12.10 |
| [211203] 코딩 테스트를 위한 파이썬 표준 라이브러리 (0) | 2021.12.03 |