모든 게시물은 macOS Monterey 12.0.1 버전 기준으로 작성하였습니다.
부스트캠프 AI Tech 3기를 위한 Pre-Course 를 토대로 작성하였습니다.

Convolution
방법은 위 이미지와 같지만 이 과정이 가지는 의미가 무엇일까?
적용되는 필터를 해당 이미지에 도장처럼 찍는 것인데 그 종류에 따라
blur, emboss, outline 등 다양한 결과가 나올 수 있다.
만약 커널이 3x3에 각 값이 1/9라면 그 커널 속 이미지의 평균이
해당 출력값으로 들어갈 것이다.
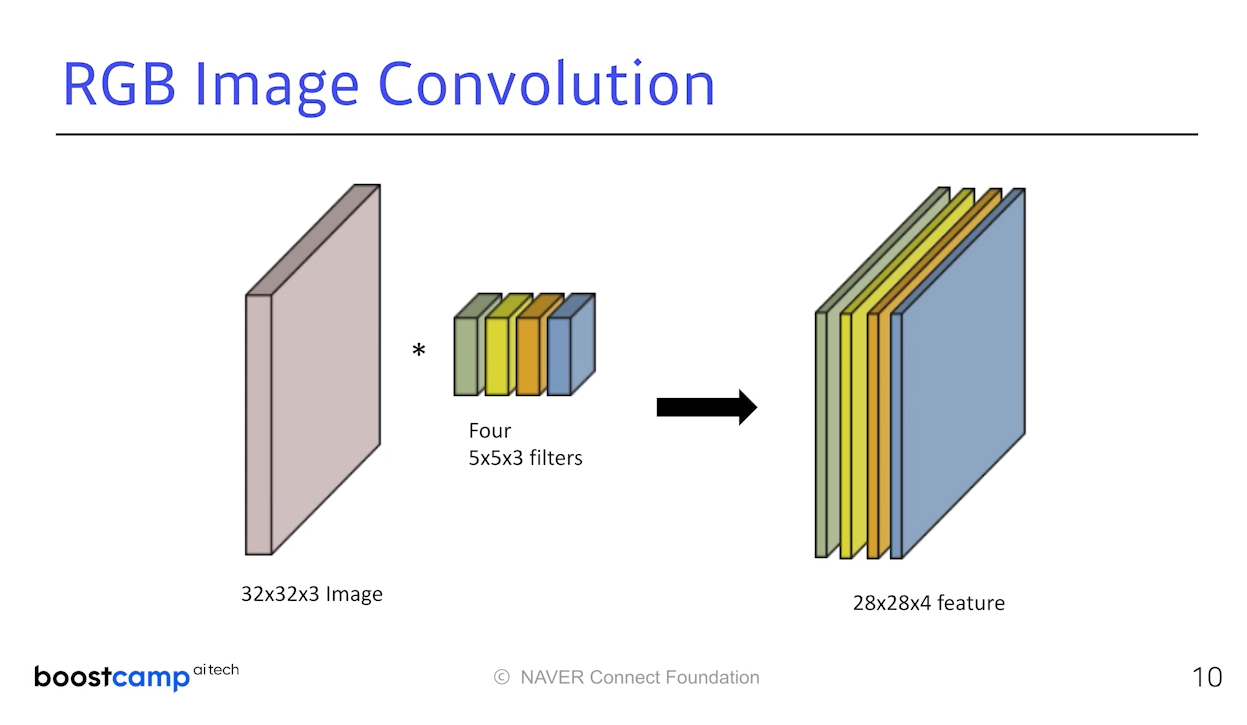
Input 채널과 Fileter 채널이 동일한 상태에서 왼쪽과 같은 과정으로 이루어지는데
오른쪽 이미지처럼 Filter 수가 늘어난다면 Output 채널 역시 늘어날 것이다.
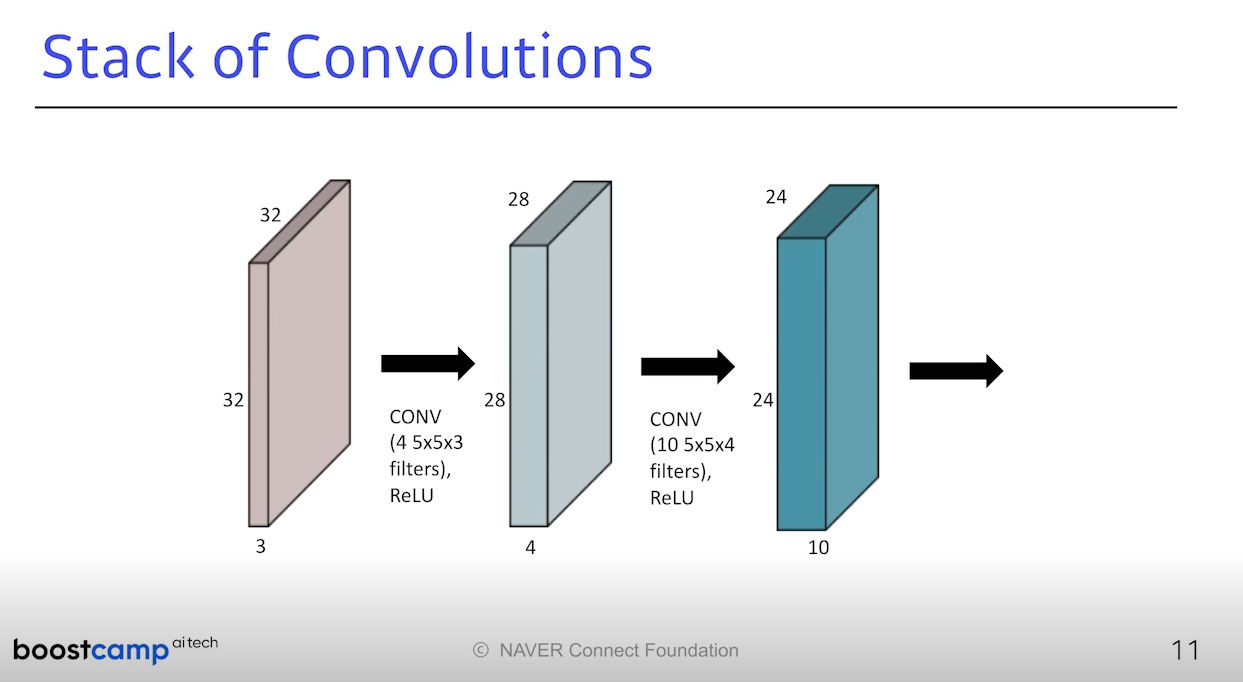
그 Convolution을 여러번 쌓고 MLP처럼 한번 Conv 연산을 하면 그 뒤에
Non-linear activation function을 통과시킨다. 위 사진을 보자.
이 연산을 정의하는데 필요한 파라미터의 개수를 고려하는 것이 중요하다.
(32,32,3)이 들어가서 (28,28,4)가 나오려면 어떤 필터가 필요할까?
채널이 4개니까 필터는 총 4개 필요할 것이다.
32-사이즈+1 = 28이므로 사이즈는 5일 것이다.
즉, (5,5,3) 커널이 4개 있어야 위 과정과 같은 convolution이 일어난다.
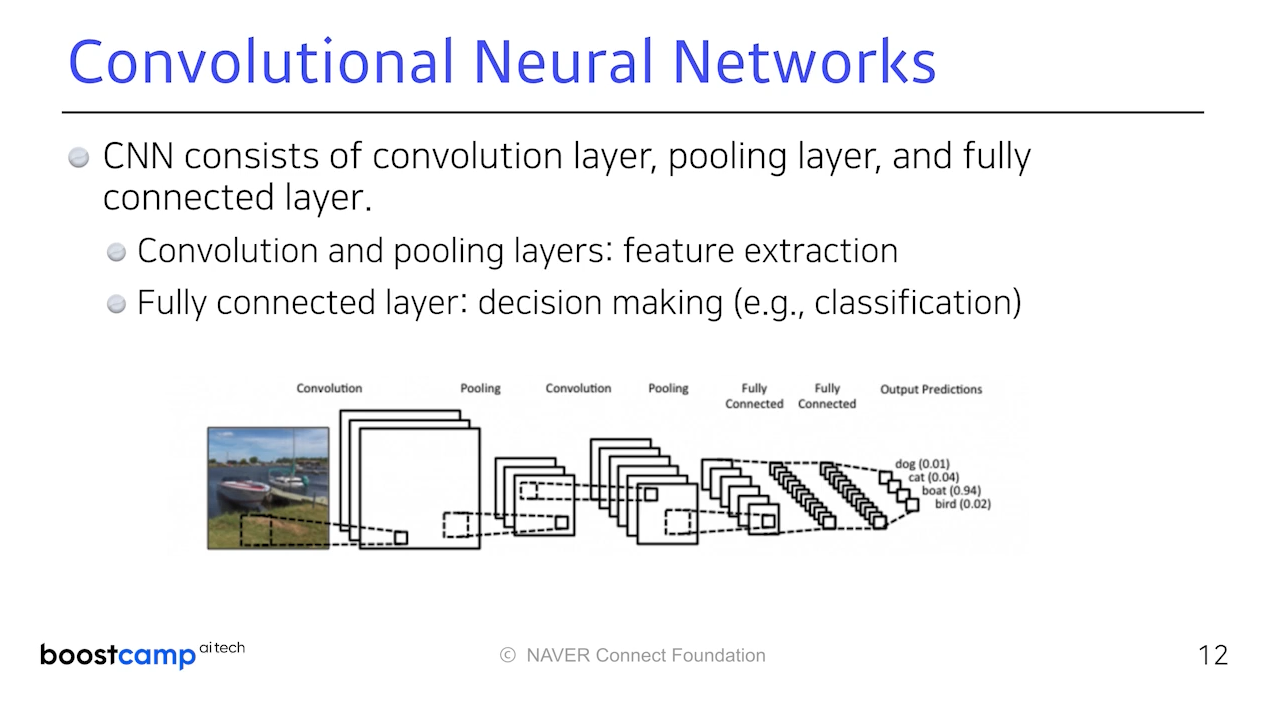
Convolution과 Pooling으로 이미지의 주요 Feature를 Extract하고,
이를 마지막에 다 합쳐서 분류, 회귀 등 원하는 결과를 얻는데 FCN을 쓴다.
요즘에는 generalization performance를 향상시킨다는 측면에서
파라미터를 줄이기 위해 FCN을 붙이지 않는 방향으로 발전하고 있다.
따라서 앞으로 새로운 모델을 볼 때도 그 파라미터 수에 대한 감이 필요하다.
이를 계산하기 위한 개념들에 대해 알아보자.
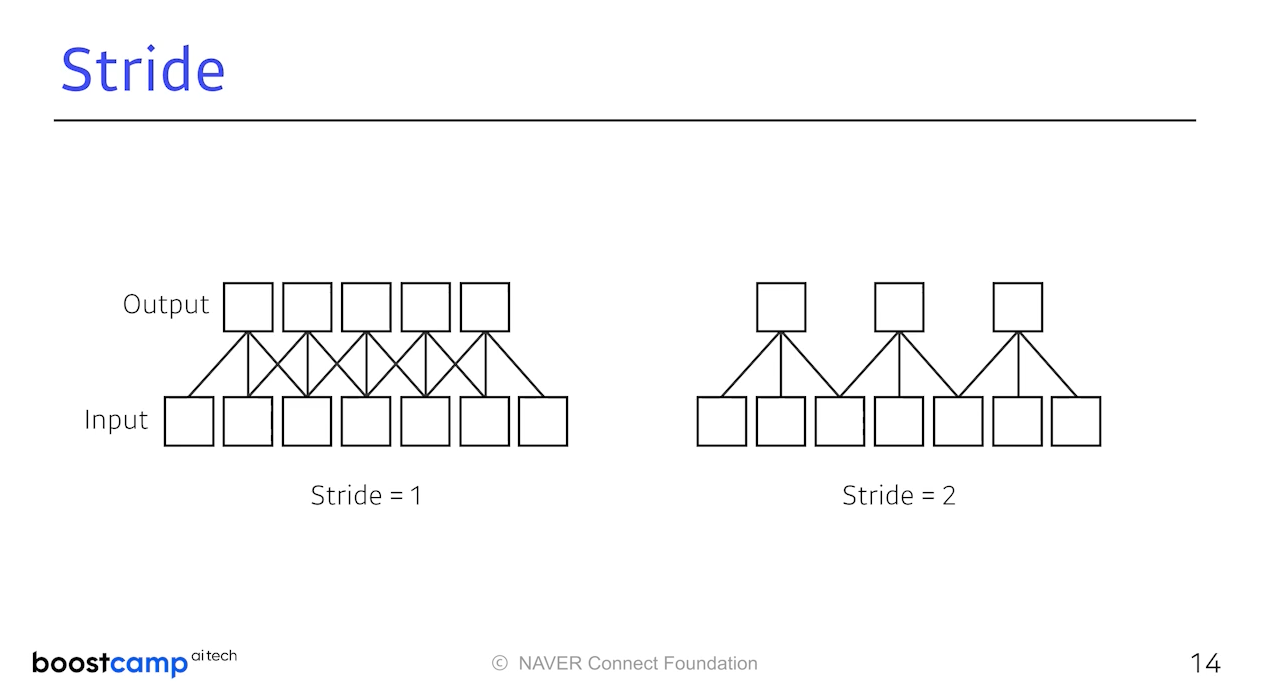
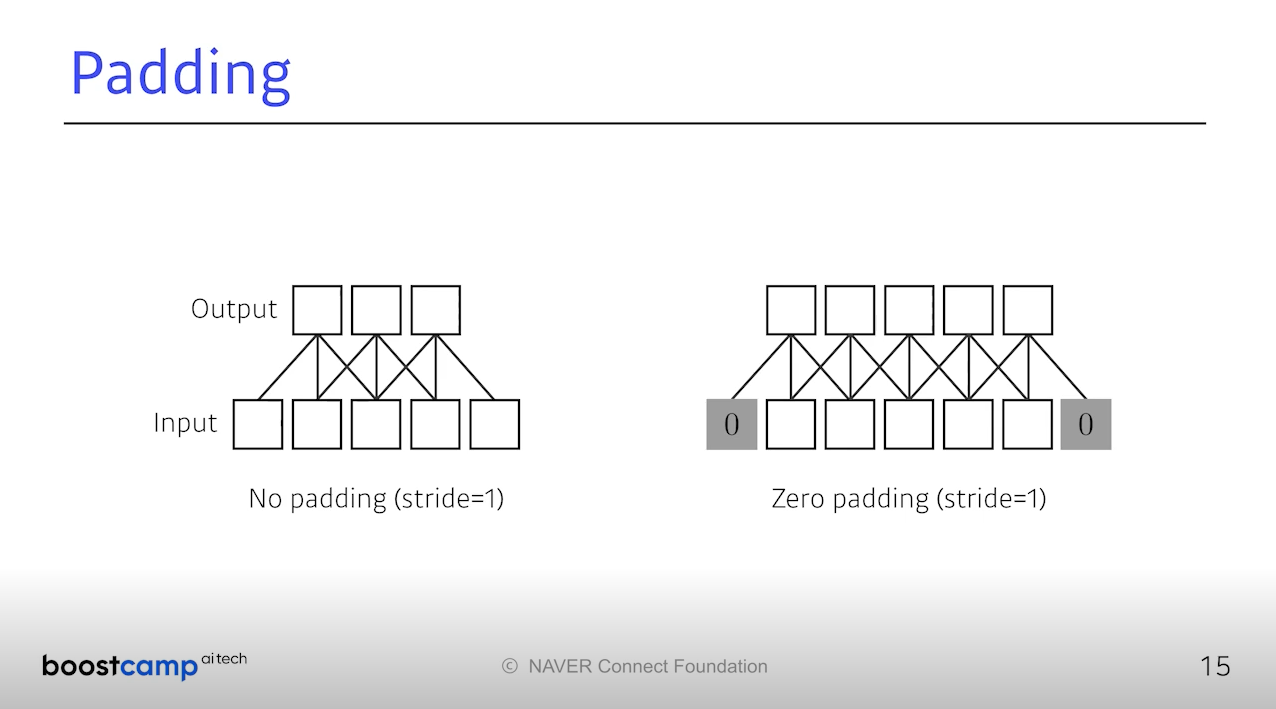
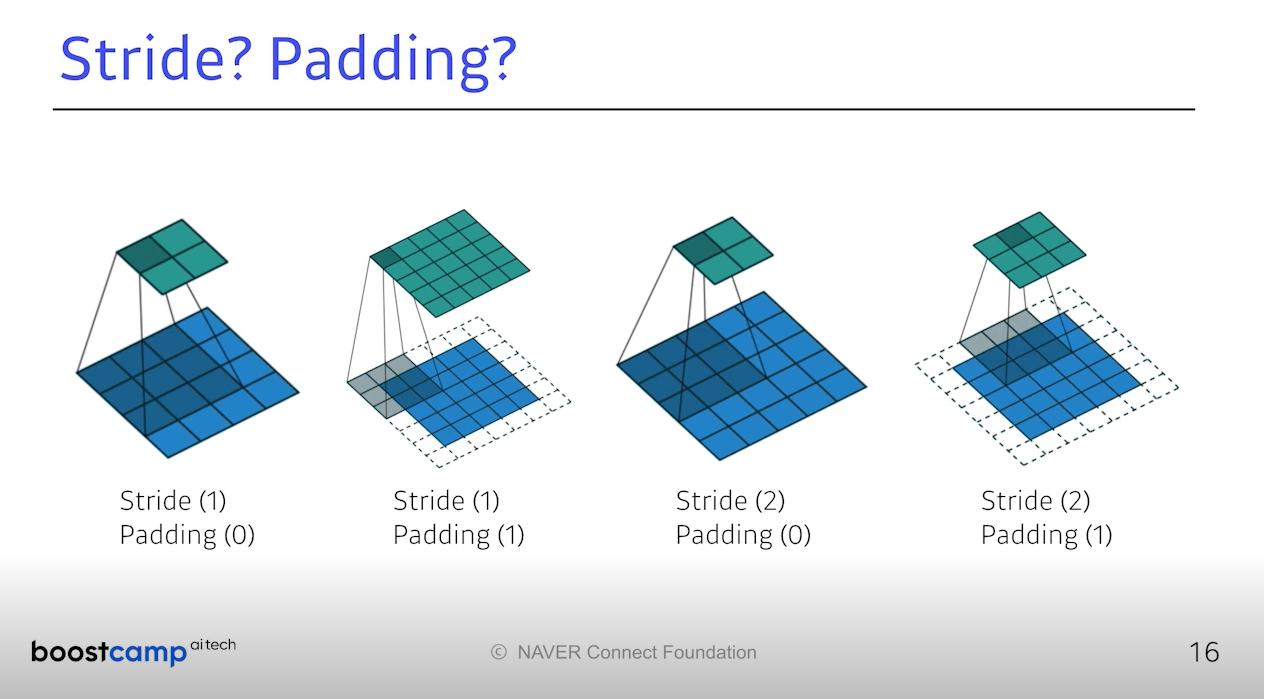
1차원에서 Stride와 Padding은 위와 같다. 특히 Padding은 우리의
이미지 정보를 잃고 싶지 않을때 가장자리를 0으로 덧대어 진행한다.
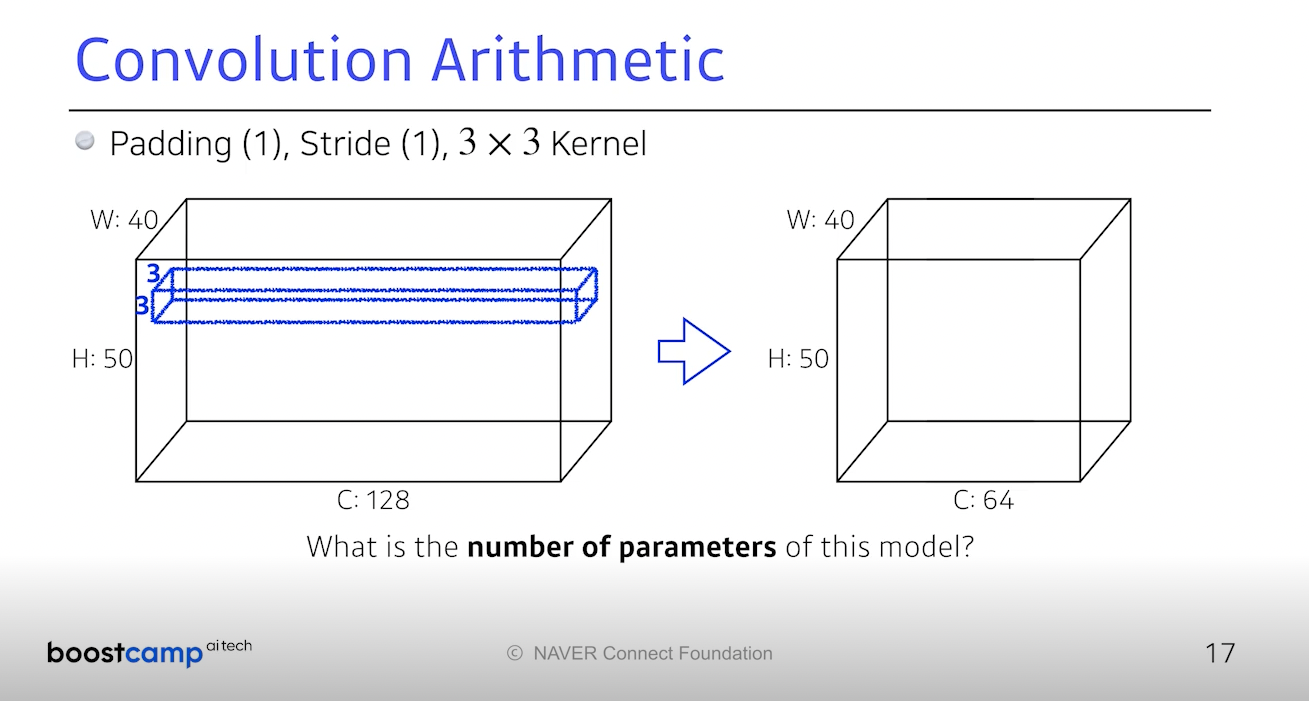
채널이 64개 나오는 것을 보니까 커널은 64개가 필요하다.
3 x 3 x 128 필터가 64 개 필요하므로 다 곱하면 73,728이 나온다.
패딩 하나, 스트라이드도 1이라면 Height, Width는 유지된다.
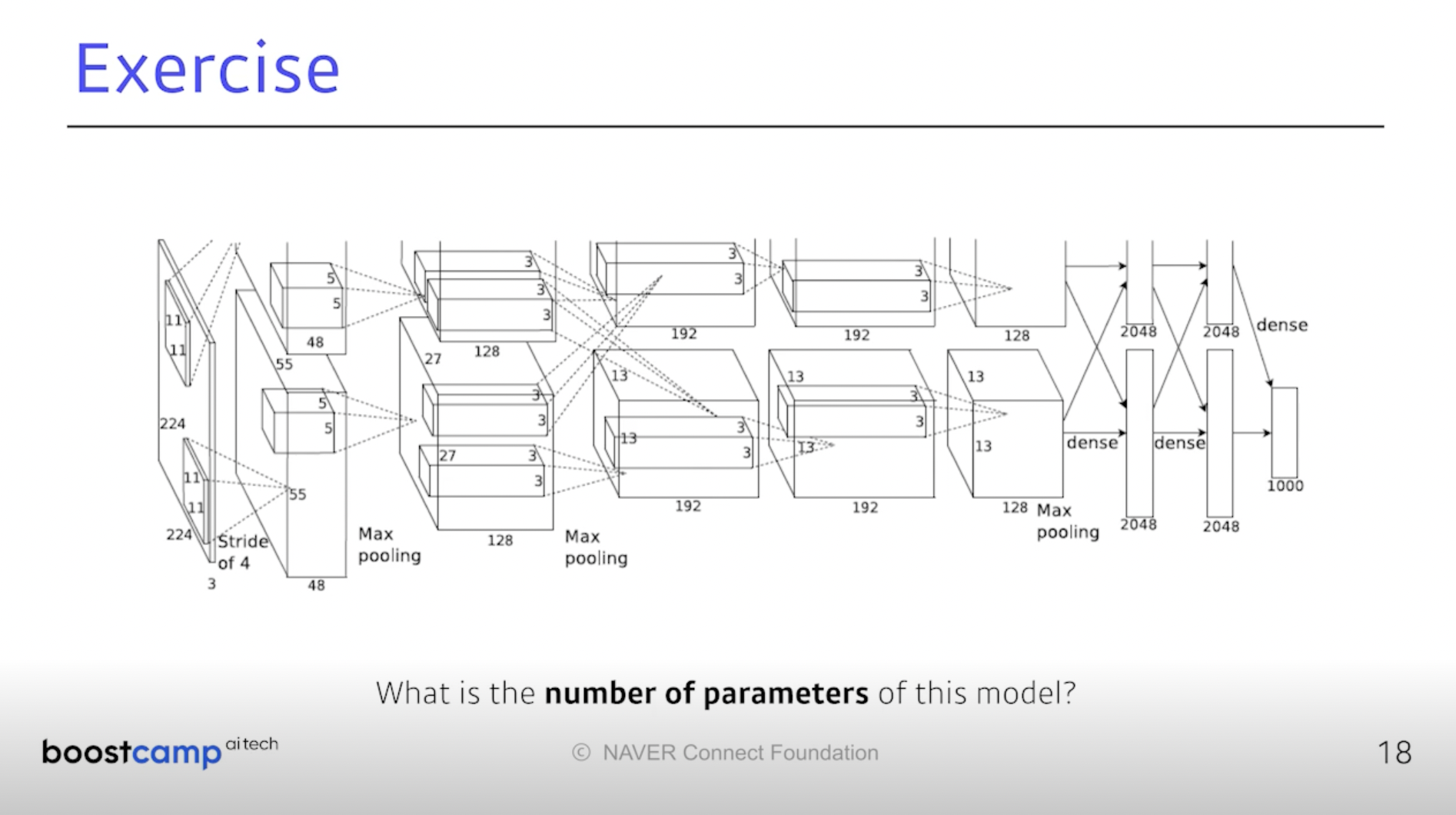
AlexNet 모델. 지금의 딥러닝 위상을 가지게 한 모델이다.
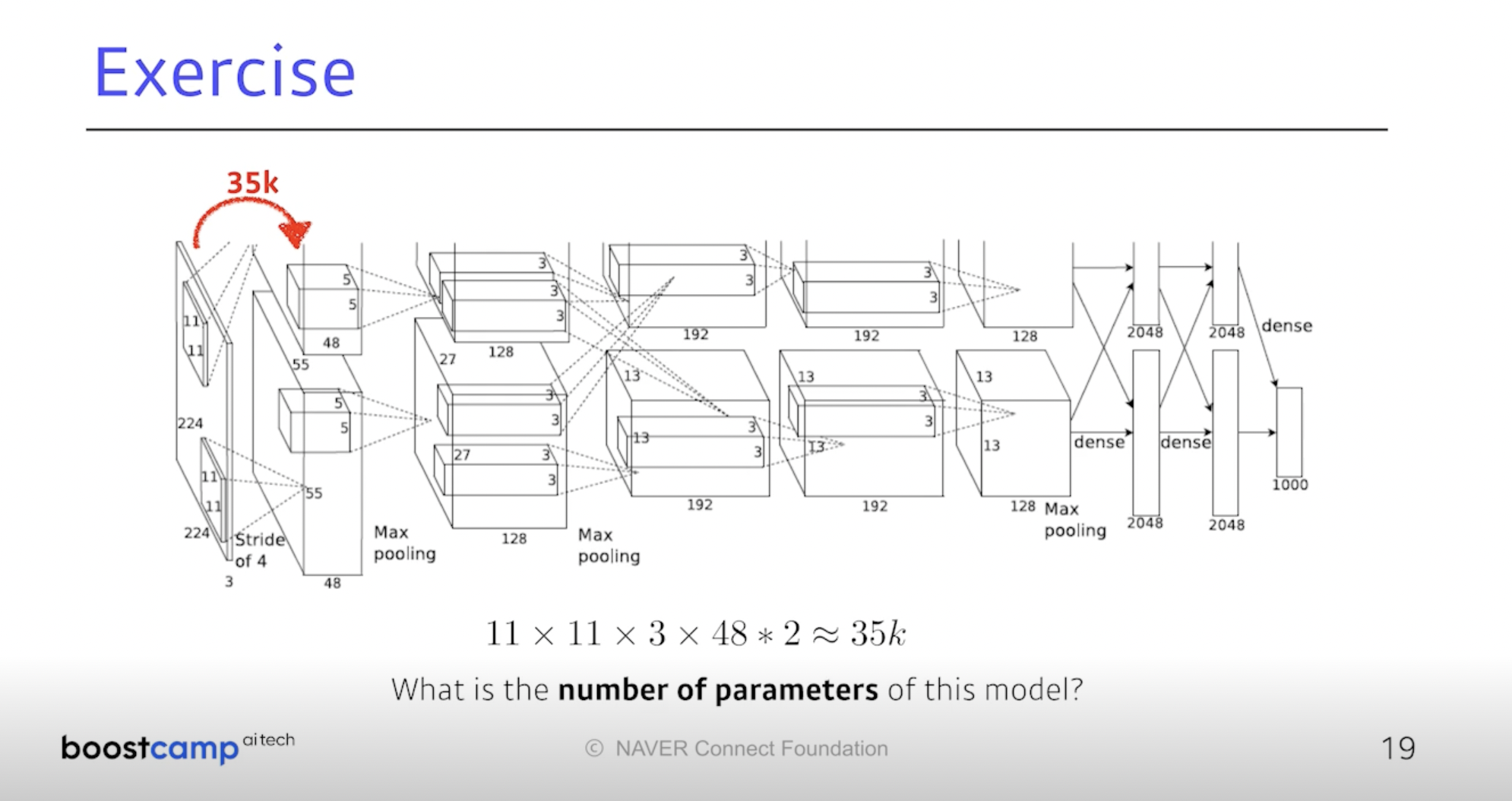
입력은 (224, 224, 3)이니까 한 개의 커널은 (11, 11, 3)이겠다.
-> 11 x 11 x 3 x 48 x 2 = 34,848개의 파라미터가 필요하다.
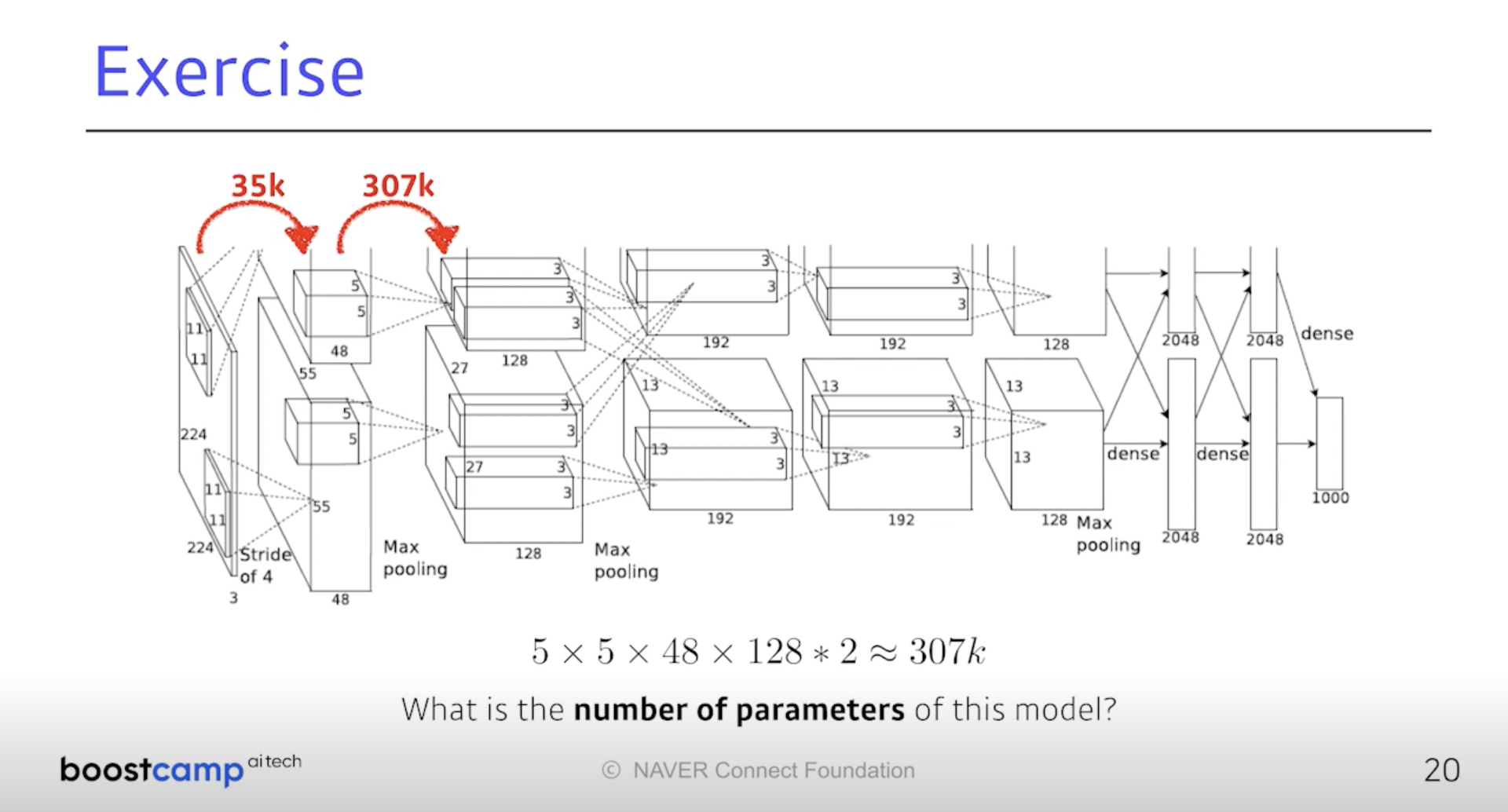
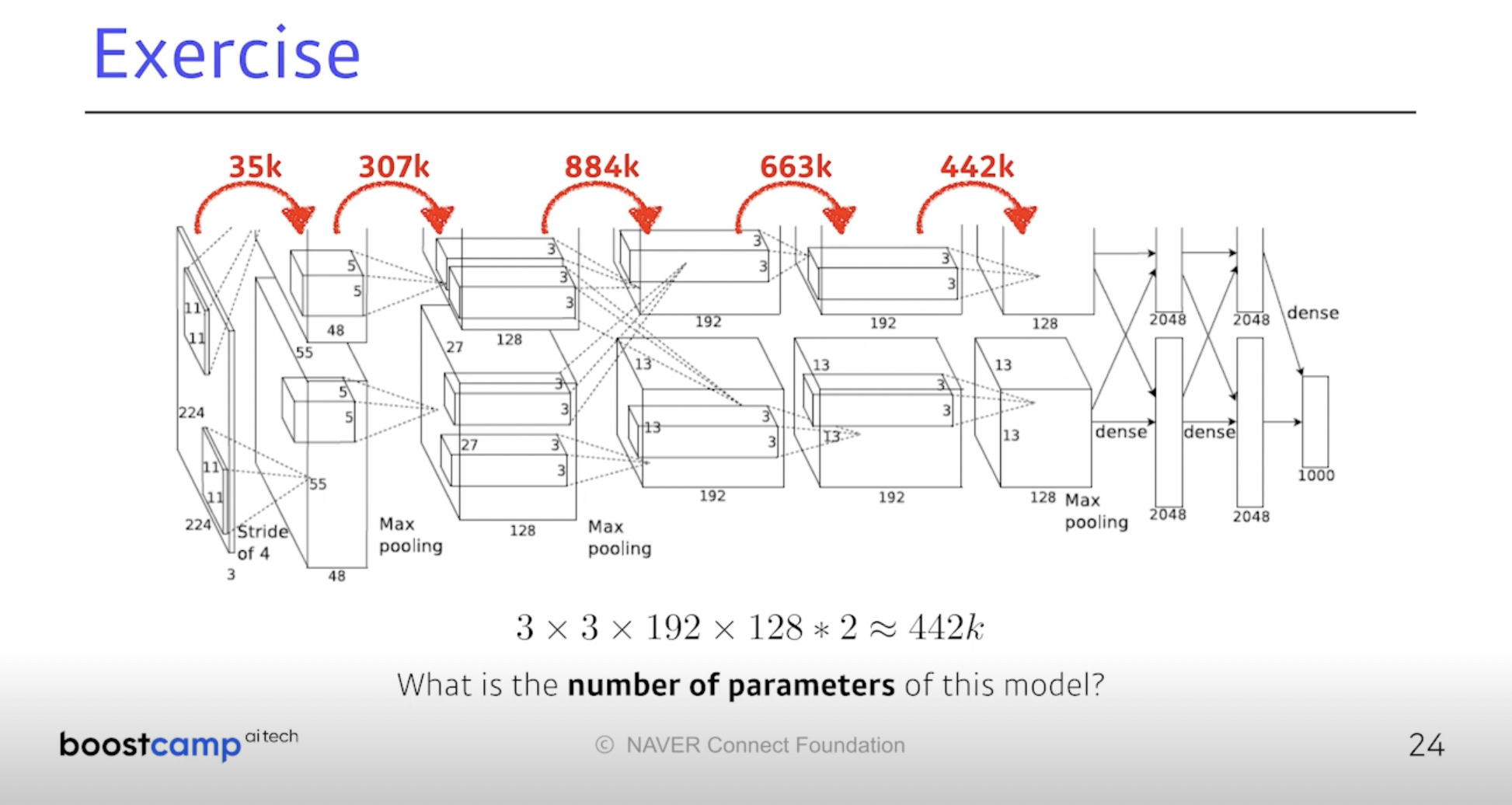
두 번째 Layer로 가면 5 x 5 x 48 x 128 x 2 = 307k
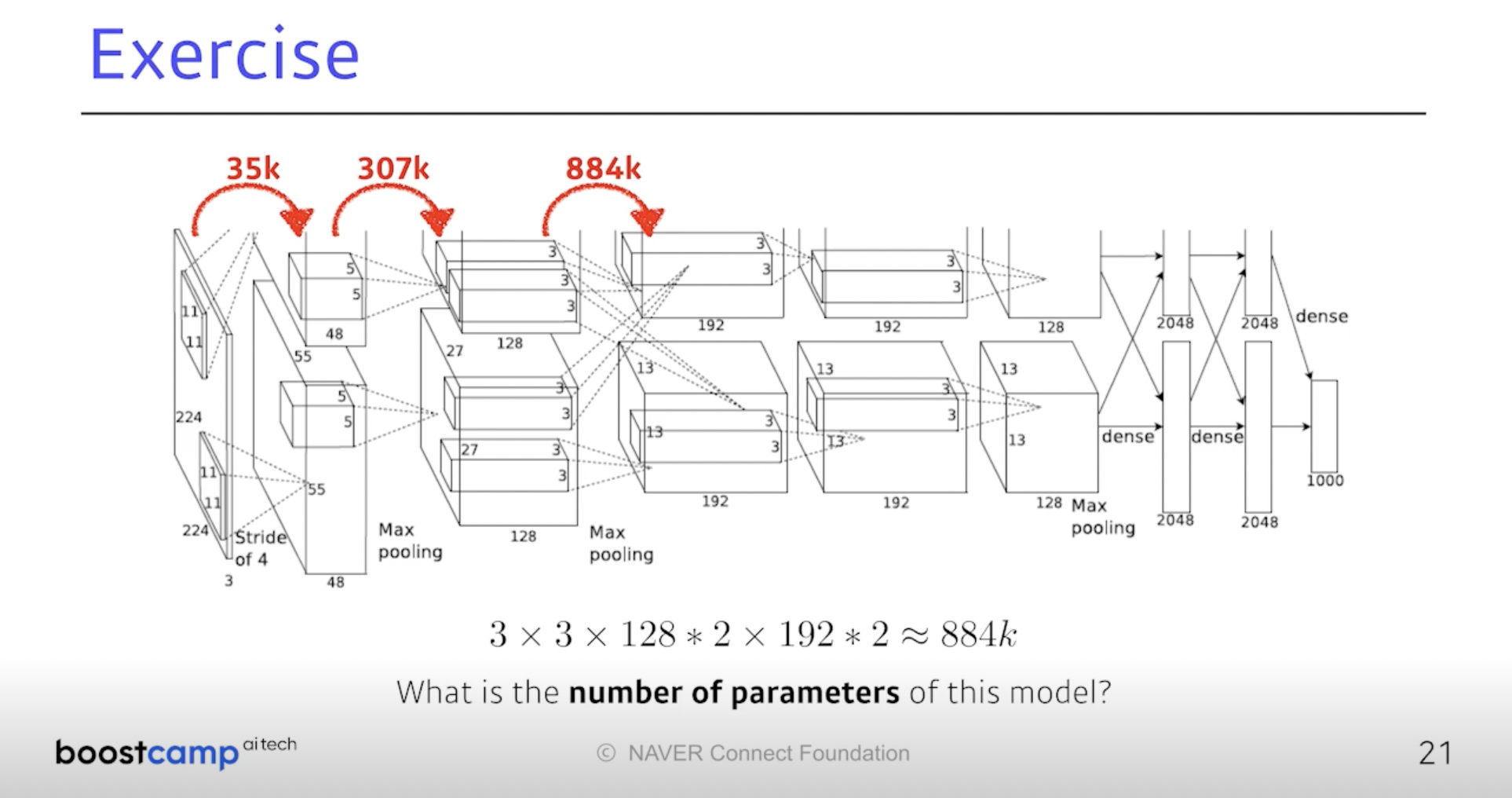
세 번째 Layer로 가면 3 x 3 x 128 x 2 x 192 x 2 = 884k
이렇게 쭉 계산을 해보며 parameter 수에 대한 감각을 기르자.
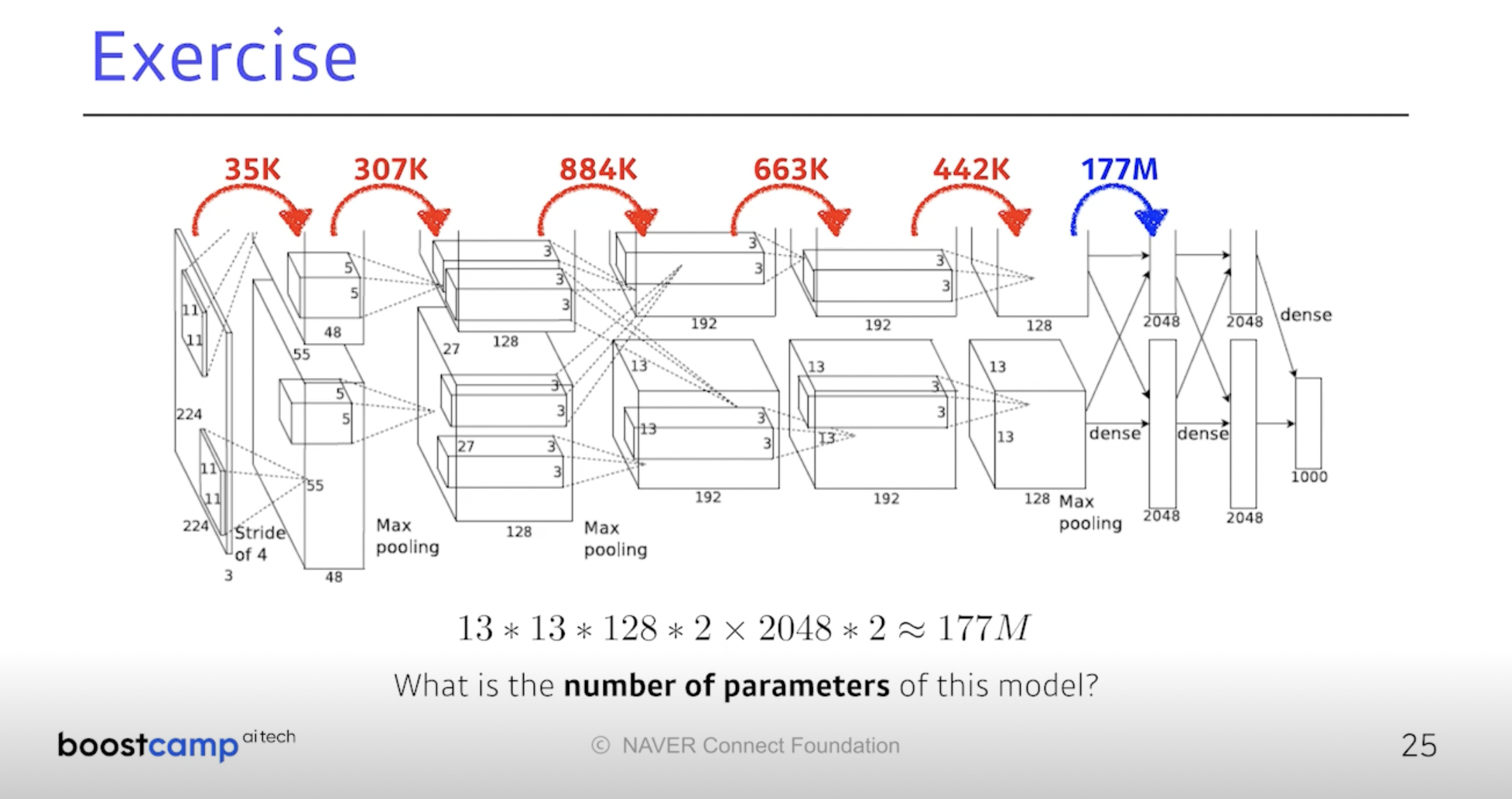

이제 13 x 13 x 128 x 2 x( 2048 x 2 ) 로 177M, 단위가 달라진다.
Dense Layer의 차원은 (인풋 뉴런 수 x 아웃풋 뉴런 수) 다.
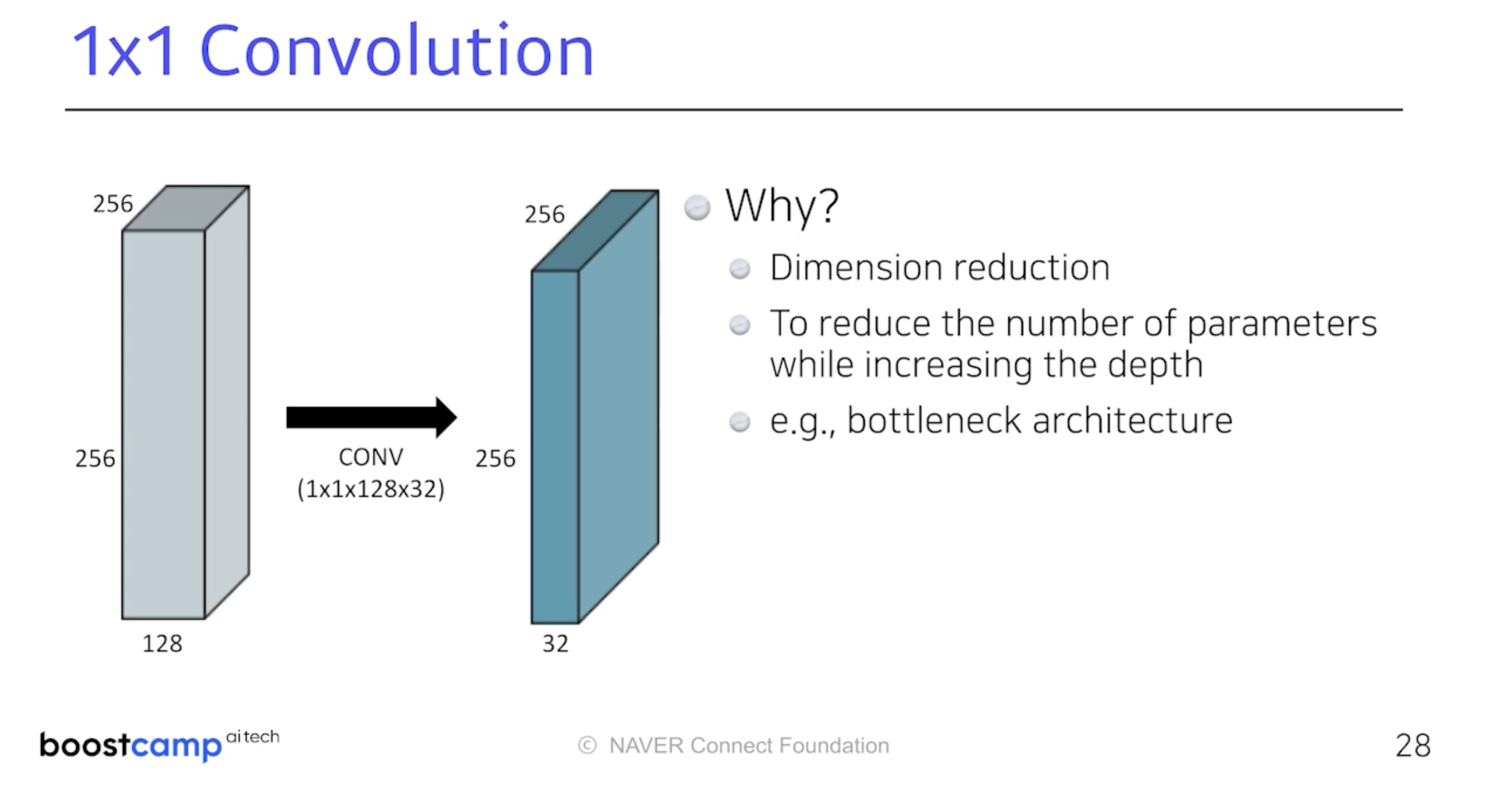
Dimension Reduction을 위한 1 x 1 Convolution
이미지에서 어떤 영역을 보는 것이 아닌 한 픽셀만 보고 채널 방향으로
줄이기 위해 사용된다. 여기서 줄인다는 dimension이 곧 채널이다.
이를 통해 모델 depth를 늘려도 파라미터 수는 Dense Layer처럼 늘리지
않을 수 있다.